This tutorial will guide you through the process of querying data in Semarchy xDM using the SQL API. You will learn how to run basic and advanced queries, as well as important integration concepts.
This tutorial is based on PostgreSQL and pgAdmin 4. You can run the same queries on SQL Developer for Oracle or SQL Server Management Studio for SQL Server, or use a universal client such as DBeaver.
Learning outcomes
- Executing basic queries in SQL.
- Executing advanced queries in SQL.
- Understanding the principles of integration.
- Querying data errors.
Learning track
This tutorial is the second SQL-based unit within the Data Publishing & Consumption track. Before beginning this unit, you must:
- Set up Semarchy xDM.
- Complete the Customer B2C demo tutorial.
- Complete the tutorial Set up an SQL client for Semarchy xDM.
If you have not completed these prerequisites, return to the Tutorials menu.
Otherwise, enjoy this tutorial!
Knowing how to query data using SQL is a critical step to building a successful MDM program.
While you ordinarily would rely on a middleware tool or a user-designed program to consume data from xDM, it is still important for you, as the integration developer, to understand the consumption methods described in this tutorial unit, starting with simple queries.
Learning outcomes
- Querying all customer golden records.
- Querying customer master and golden data side-by-side.
- Querying customer golden data using a source ID.
Get all customer golden records
The most basic query selects Person records from the golden data (GD) table. You will also select specific columns which is a more useful query for analyzing data.
- Run the following query in pgAdmin (or another SQL client) to select all columns from the Person golden data (
GD_PERSON) table:
select
gd.*
from
gd_person gd;
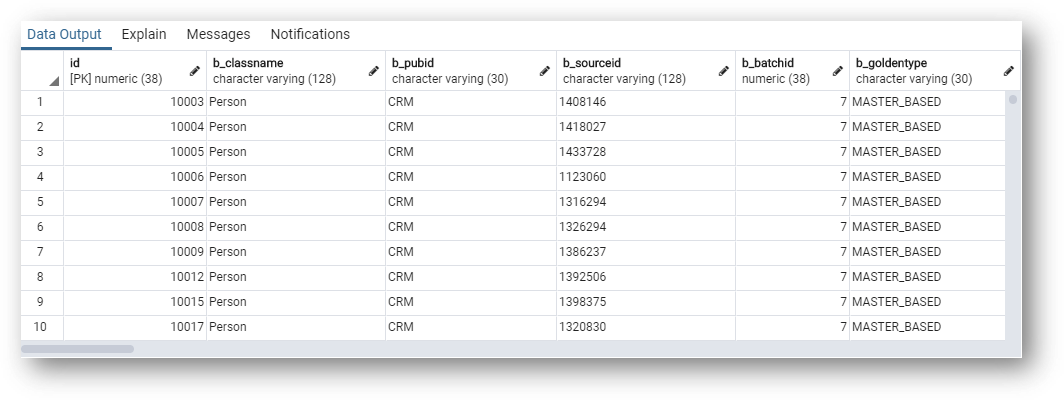
These are all the customer golden records, with all available columns.
- Run the following query to select only the golden record
ID,first_name, andlast_namecolumns:
select
gd.id,
gd.first_name,
gd.last_name
from
gd_person gd;
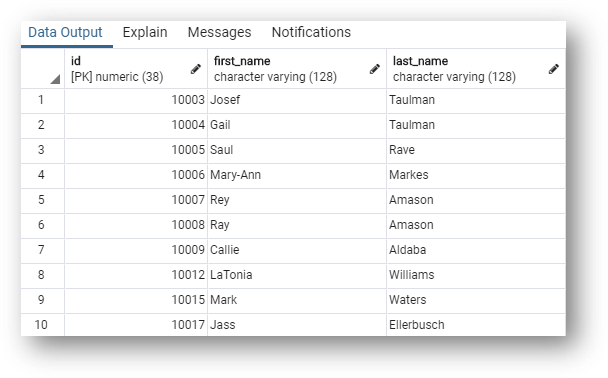
These are all the customer golden records with only the golden record ID, first_name, and last_name columns.
Get master and golden records side-by-side
When looking at matched customer records, it is useful to analyze groups of master records alongside the resulting golden record, in order to compare how the master records were deduplicated. To get this view, you must join the master data (MD) table with the golden data (GD) table:
- Run the following query to select the publisher ID, source ID, first name, and last name from the master records, as well as the golden record ID, first name, and last name from the golden records.
select
md.b_pubid publisherid,
md.b_sourceid sourceid,
md.first_name masterfirstname,
md.last_name masterlastname,
gd.id goldenid,
gd.first_name goldenfirstname,
gd.last_name goldenlastname
from
md_person md
inner join gd_person gd on gd.id = md.id
order by gd.id asc;
The join is on the golden ID, which appears on both the master and golden tables.
- Observe the differences between master (highlighted in blue in the screenshot below) and golden (highlighted in yellow) data.
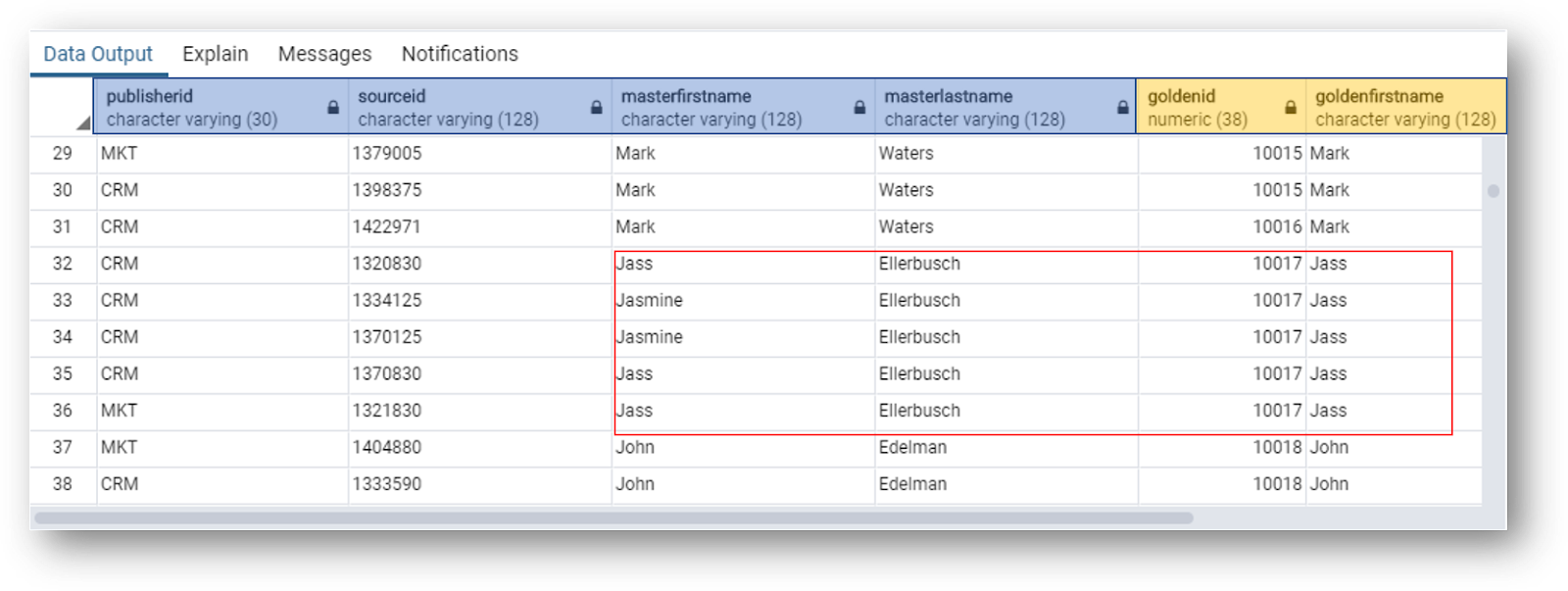
- Have a closer look at customer Jass Ellerbusch (golden record ID 10017):
- This customer has master records with different spellings for their first name.
- The corresponding golden record has standardized the spelling of their first name.
Next, you will get a golden record given the source ID.
Query golden records with a given source ID
At times, you might need to look up a golden record, but all you have is an ID from the source system. To query the golden records when you know their source ID, proceed as follows:
- Run the following query to select the golden record related to a source record from the CRM system having source ID 1483060.
select
md.b_pubid publisherid,
md.b_sourceid sourceid,
md.first_name masterfirstname,
md.last_name masterlastname,
gd.id goldenid,
gd.first_name goldenfirstname,
gd.last_name goldenlastname
from
md_person md
inner join gd_person gd on (
gd.id = md.id
)
where
md.b_pubid = 'CRM'
and
md.b_sourceid = '1483060'; /* SourceID */
- Have a look at the result of the query:
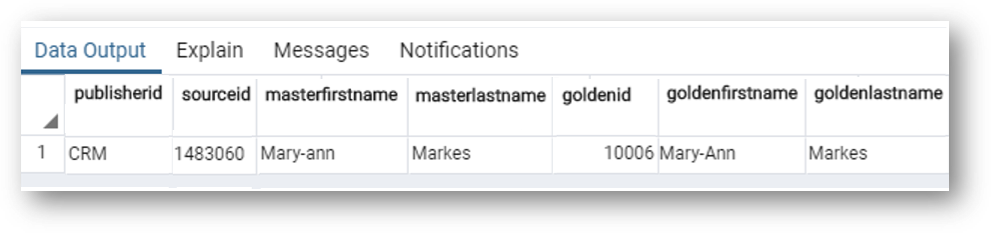
- The first four columns respectively provide the publisher ID, source ID, first name and last name from the master record.
- The
sourceIdcolumn contains the source ID which allows us to retrieve the corresponding golden record. goldenId,goldenFirstName, andgoldenLastNameare from the related golden record.- Notice that the source system is using the first name Mary-ann, while the golden record has consolidated to the normalized first name Mary-Ann.
Congratulations!
You have successfully run basic queries via SQL to get information in xDM.
In this section, you created:
- A simple query to get all customer golden records.
- A query to get master records and the corresponding golden records.
- A query to get the golden record given an ID from a source system.
Next, you will execute advanced queries to retrieve information, such as customer records and the products they purchased.
Now that you are familiar with basic SQL queries, this section will delve into advanced queries to expand the scope of analyses you can perform.
Learning outcomes
- Querying customer records and the products they purchased.
- Querying customer master records to see the duplicates side-by-side with the golden records.
Query customers' records and their products
You can query customers and see the products they have purchased. This is useful for analytics and BI tools to answer questions like "Which customers have purchased a certain product?" or "Who are our top-paying customers?"
- Run the following query to select the customer's golden record ID, first name, last name, and the products each customer has bought.
select
pe.id,
pe.first_name,
pe.last_name,
pr.product_name
from gd_person pe
inner join gd_person_product pp on pe.id = pp.f_person
inner join gd_product pr on pr.id = pp.f_product
order by pe.first_name desc;
- Have a look at the results:
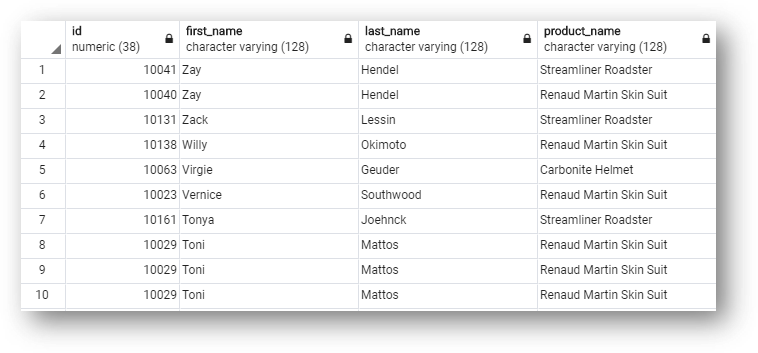
- The first three columns contain data from customer golden records: golden ID, first name, and last name.
- The fourth column contains the products purchased by customers
- Notice customers that have ordered more than one product (one row per customer and product).
- You may see duplicate customers if you have not yet completed the "Customer B2C demo" tutorial where you manually confirm or merge match suggestions.
Next, you will query master records to see the corresponding duplicate masters.
Side-by-side duplicates
In this section, you will learn to query a specific master record and see the corresponding master records that are considered duplicates side-by-side. The query will also show the corresponding golden record that the master records consolidate into.
- Run the following query:
select
md.b_pubid dup1_publisher,
md.b_sourceid dup1_id,
md.first_name dup1_first_name,
md.last_name dup1_last_name,
md2.b_pubid dup2_publisher,
md2.b_sourceid dup2_id,
md2.first_name dup2_first_name,
md2.last_name dup2_last_name,
gd.id gold_id,
gd.first_name golden_first_name,
gd.last_name golden_last_name
from md_person md
inner join gd_person gd on (
gd.id = md.id
)
inner join md_person md2 on (
md.id = md2.id
)
where md.b_pubid = 'CRM' /* Publisher ID */
and md.b_sourceid = '1419728' /* Source ID */
/* and md.b_pubid = md2.b_pubid */ /* uncomment this line to restrict the duplicates to those within the CRM application */;
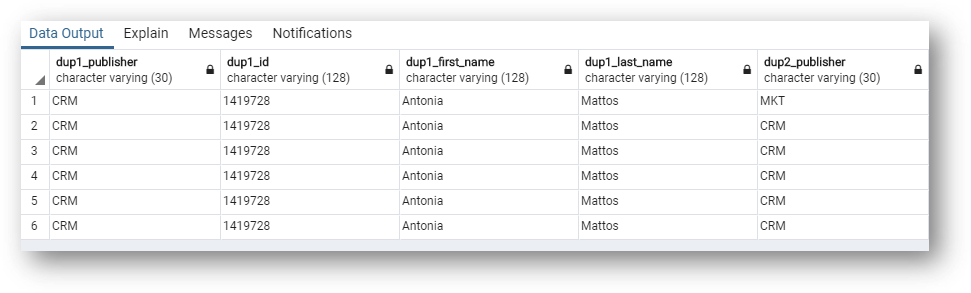
- This query filters on the source ID 1419728 from the CRM system.
dup1_columns come from the master record that you filtered on.dup2_columns come from the corresponding master records identified as duplicates to the record that you filtered on.- The
golden_columns come from the golden record that the master records roll up to.
- Note that the
dup2_publisheranddup2_idcolumns show the master records that matched with the record of Antonia Mattos with ID 1419728 from CRM.
Congratulations!
You have successfully run advanced queries via SQL to get information in xDM.
To summarize, you have created:
- A query to get all customer golden records and the products each customer purchased.
- A query to see the master records from a specific customer to compare the duplicate source data side-by-side and get the corresponding golden record.
Next, you will learn how integration works to understand the concepts to allow you to write your own queries.
Now that you have explored a data location with several SQL queries, it is time to learn more about some integration concepts.
Learning outcomes
- Gaining insight into fundamental aspects of publishers.
- Exploring the various record types handled by Semarchy xDM.
- Understanding the role of the certification process, matching rules, and survivorship.
- Discovering the different types of entities in Semarchy xDM.
Publishers
When you load data into xDM, we refer to the source applications where the data came from as publishers.
An application that publishes data into xDM is assigned a publisher code in the Application Builder. This code is known as the publisher ID and is loaded into the column b_pubid.
The publisher ID is necessary for loading data. It is also useful when you query data to trace which applications the master data came from. xDM displays the publisher ID in the master record's ID in the Customer B2C Demo application.
Types of records
Semarchy xDM deals with several types of records that correspond to different steps of the integration process:
- Source data: this is the raw data coming from publishers or direct authoring in Semarchy xDM. Source data tables contain all source data received from a publisher (not only the latest).
- Master data: this corresponds to the latest data sent by a publisher, validated and enriched. It is still attached to a publisher and linked to source data.
- Golden data: this is the consolidated data from merged master records. It is validated and certified data, ready to be consumed in the data UI or by downstream systems. It is still attached to a publisher based on the preferred publisher specified in the survivorship rule.
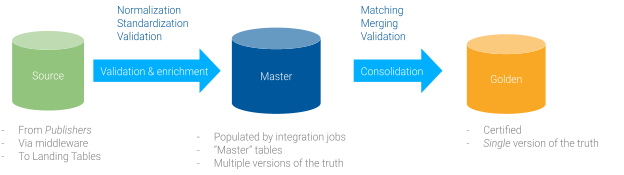
The transformation process from source records to golden data within Semarchy xDM is called the data certification process or integration process.
Matching and survivorship
Matching is a key step within the data certification process. Its role is to detect duplicates to consolidate them into a golden record. There are two different types of matching:
- Fuzzy matching: records are matched by detecting similar values between the different records.
- ID matching: exact matches are created based on the records' primary key attribute.
When records are matched together, survivorship rules select for a given attribute the most appropriate value from the various source records.
Entity types
Each entity you design in the Application Builder has a given entity type that defines the entity's capabilities for matching, merging, and authoring. Entity types are:
- Fuzzy-matching entities: entities coming from multiple sources that do not share a common identifier.
- ID-matching entities: entities coming from multiple sources sharing a common identifier.
- Basic entities: for entities coming from a unique source.
Congratulations!
You have gained a better understanding of fundamental integration concepts in xDM.
Next, we will have a more detailed look at each type of entity.
If you have two records with the same ID in different systems, duplicate data within the same system (which is common with customer data), or no common identifier across systems, you will need to match records and consolidate them to become a "best-of-breed" golden record.
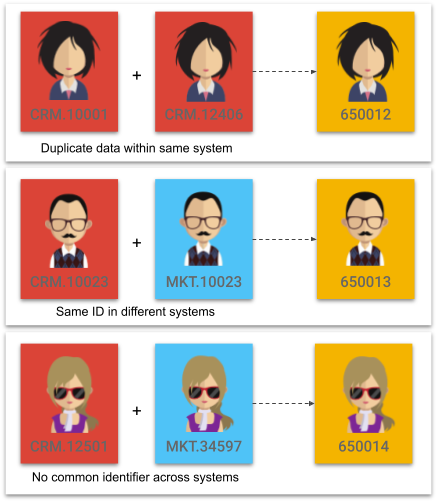
Fuzzy-matching entities
A fuzzy-matching entity is designed to handle the scenario where there is no common identifier across systems. A golden record ID will then be generated when records are consolidated. As such, you will define match and survivorship rules with a fuzzy-matching entity.
We will now look at how primary keys work in fuzzy-matching entities.
Fuzzy-matching-entity primary keys
The primary key is useful for filtering data in your queries, as you learned when querying golden records based on a given source ID.
- For the source data, source error, and master data (SD, SE, and MD) tables: this key is composed of the source system identifier (
b_sourceidcolumn) and publisher code (b_pubidcolumn). - For golden data: when records are consolidated into a golden record (GD and GE tables), a system-defined primary key is generated. This golden record ID is stored in the
IDcolumn. - For master data: the MD table makes the bridge between the source ID and the golden ID as it contains both these values.
In practice
Here is an example of a fuzzy-matching entity:
- Navigate to the Customers view under the Browse Data section of the navigation drawer. Customer data is modeled using a fuzzy-matching entity.
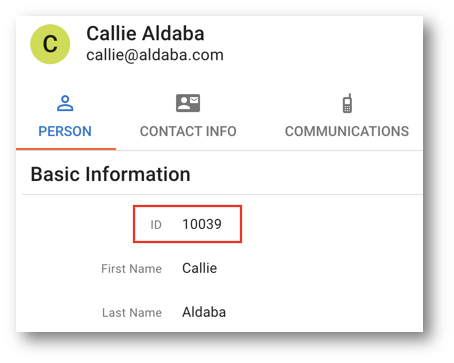
- Look for the Person record with the name Callie Aldaba.

- Click on this customer to explore their information. Note the value of the golden record ID (in our example, 10039).
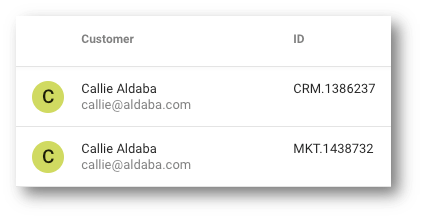
- Navigate to the Master records tab.

- Note the two master records that contributed to this customer's golden record: CRM.1386237 and MKT.1438732.
We will retrieve these values in the database later on.
- Now, switch to your SQL client and take a look at the database.
- Start by querying the
GD_PERSONtable:
select
gd.*
from
gd_person gd;
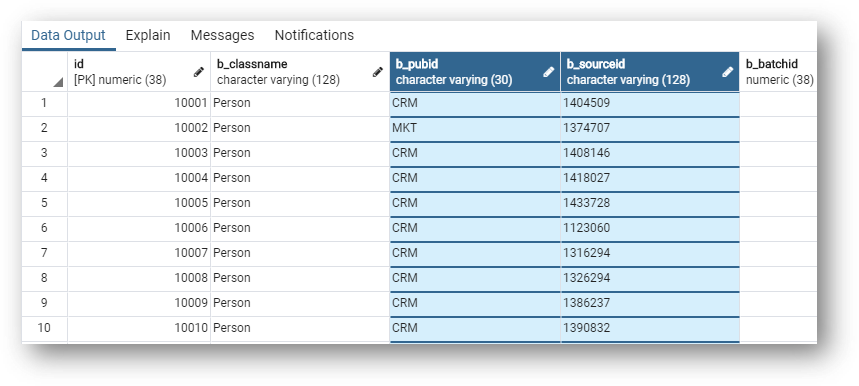
The golden data customer table (GD_PERSON) contains the golden record ID (ID column).b_pubid and b_sourceid are the publisher ID and source ID which won the survivorship process.
- Continue exploring by scrolling right.
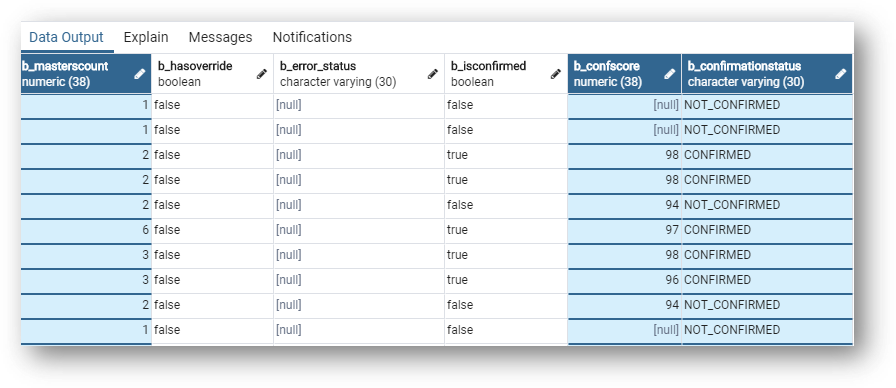
b_mastercount is the number of master records underlying the golden record.b_confscore is the confidence score of the matching and b_confirmationstatus indicates whether master records have been confirmed within a golden record or not.
- Scroll to the right again.
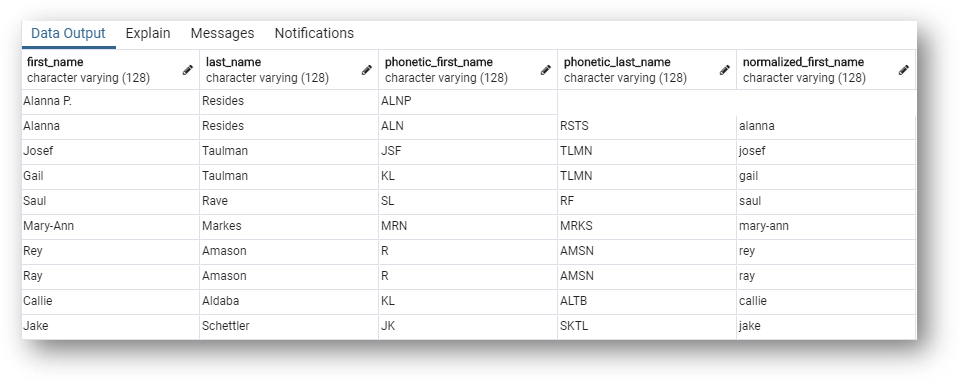
These are the golden data fields of the values that have won the survivorship process.
- Query the master table
MD_PERSON:
select
md.*
from
md_person md;
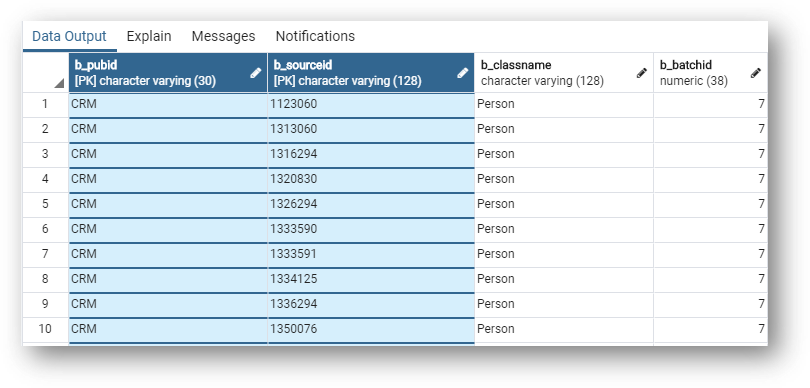
Observe that the master data table stores the publisher and source IDs as primary keys.
- Scroll to the right until you find the
IDcolumn: this column provides the golden record ID associated with the master record.
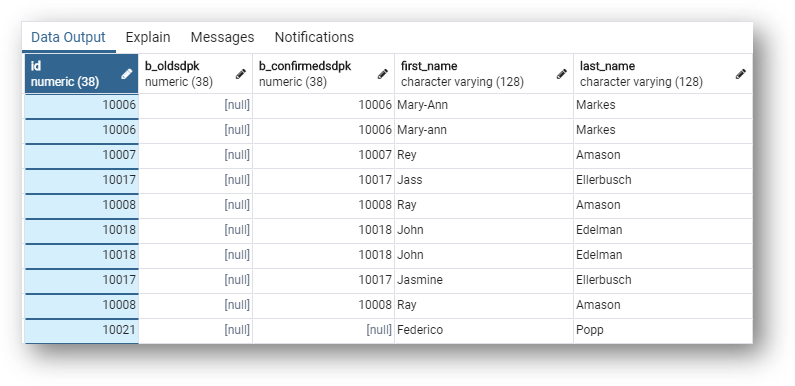
Also note that the MD table stores information about the matching process, such as match group (b_matchgrp), confirmation status (b_confirmationstatus), confidence score (b_confscore), and suggested merge ID (b_suggmergeid).
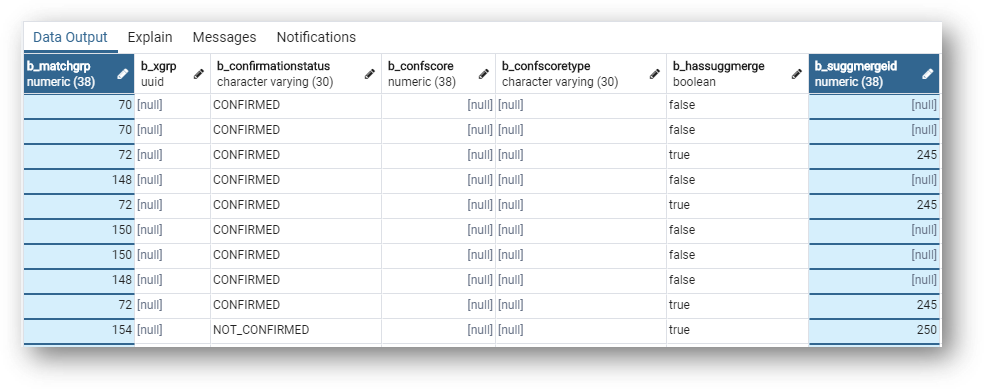
- Now run the following query to retrieve all master records related to the Customer golden record of Callie Aldaba—substitute
/* golden ID for Callie Aldaba */with the ID you retrieved in the Customer B2C Demo application (10039in our example):
select
gd.id golden_id,
gd.first_name golden_first_name,
gd.last_name golden_last_name,
md.b_pubid md_pub_id,
md.b_sourceid md_sourceid,
md.first_name md_first_name,
md.last_name md_last_name
from md_person md
inner join gd_person gd on (
gd.id = md.id
)
where gd.id=10039 /* Golden ID */
This query returns the same master records as the ones observed using the user interface:

Fuzzy-matching-entity foreign keys
Because fuzzy-matching entities separate the publisher and source IDs in their primary keys, the references to fuzzy-matching entities, likewise, have foreign keys that separate publisher and source when it comes to source data.
Consider the following example, featuring the SD_COMM_CHAN_PREF table: the foreign key to Person source data in the SD_COMM_CHAN_PREF table is composed of two columns:
FP_PERSON: references the customer source/master publisher ID.FS_PERSON: stores the source ID.
For golden data, the foreign key references the xDM system-generated ID and therefore uses a single column for the foreign key. For example in SD_COMM_CHAN_PREF, F_PERSON references the Customer golden record ID.
To illustrate that, we will start by reviewing references among entities.
- To do so, open your model diagram.
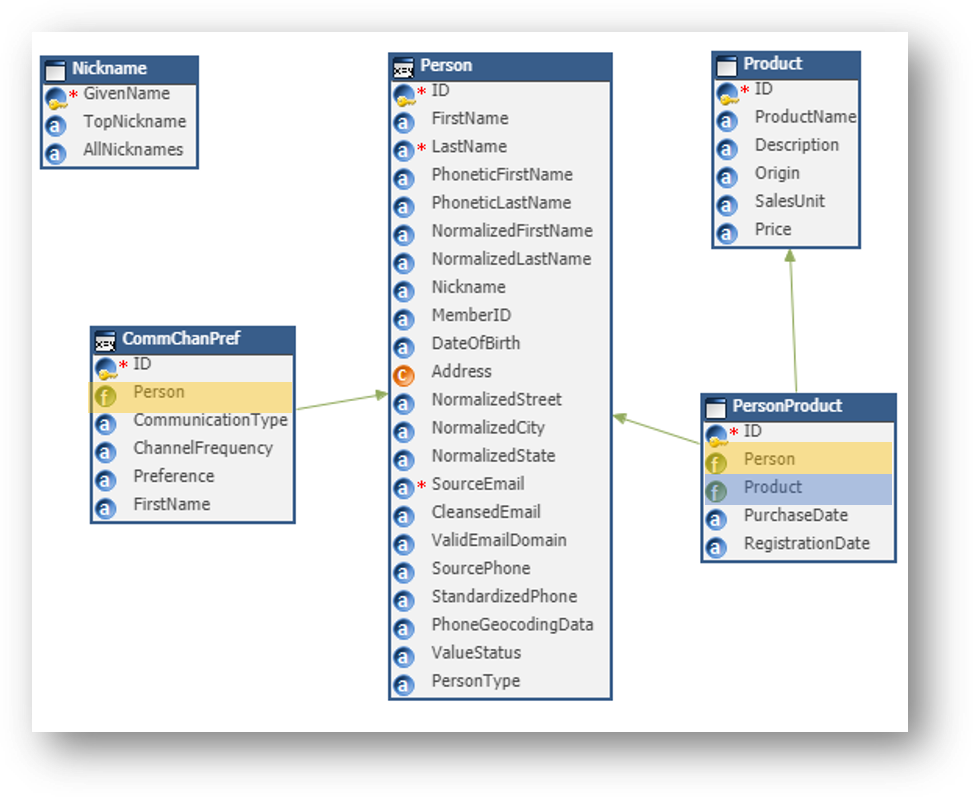
- Person is the parent entity.
- CommChanPref is one of its children and therefore has a foreign key for the Person entity.
- PersonProduct is a child of Person and Product and thus has one foreign key for each of them (many-to-many association).
- Now, compare it to how the references are created in the database foreign keys for Communication Channel Preferences. To do so, look at the table
GD_COMM_CHAN_PREFin pgAdmin. - In the
GD_COMM_CHAN_PREFtable, scroll to the far right.
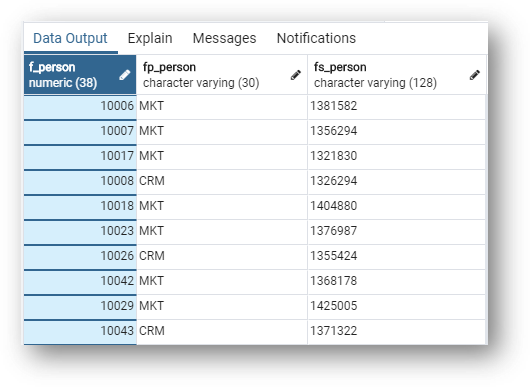
The F_PERSON foreign key is the parent Person golden record ID. In the same way, FP_PERSON is the parent publisher ID and FS_PERSON is the parent source ID.
- Now, repeat the process for
GD_PERSON_PRODUCT. Remember that PersonProduct is a child of the fuzzy-matching entity Person and basic entity Product.
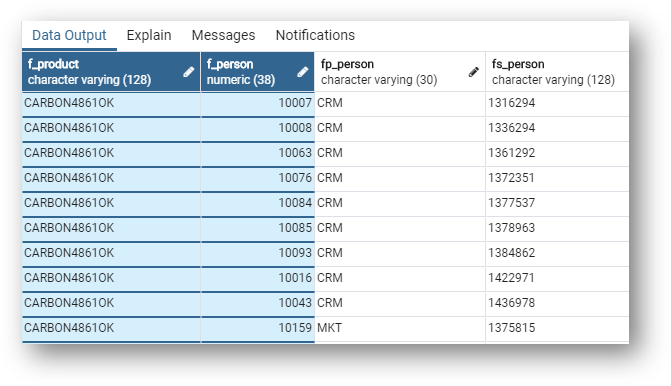
You can see that it contains both Product and Person foreign keys.
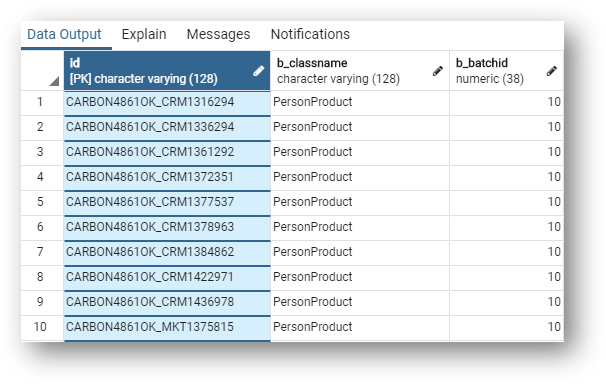
- Finally, notice that the primary key for the PersonProduct entity is concatenated from the columns
F_PRODUCT,FP_PERSON, andFS_PERSON.
ID-matching entities
ID-matching entities assume that data comes from several applications that share a common ID.
Records in entities using ID matching are matched if they have the same ID and then merged into golden records. For such entities, the golden record ID is the common source ID (no ID is generated).
This entity type is well suited when there is a truly unique identifier for all the applications communicating with the MDM hub.
Congratulations!
You have gained a better understanding of ID- and fuzzy-matching entities, along with insights into how they function in xDM.
Next, you will learn about basic entities.
Definition
In contrast to fuzzy-matching entities, basic entities are designed to handle data coming from a unique data source and thus do not support match and merge. This is suitable for simple reference data entities or when data is authored exclusively in the hub. In the latter case, xDM serves as a source system for authoring data.
Querying data in a basic entity is simpler than in a fuzzy-matching entity because the ID is the same across the source and golden (SD and GD) tables. Also, basic entities do not have the concept of a publisher or MD/MI tables. Therefore, you can use the same identifier in the source system to query basic entity records in the SD and GD tables and bypass joining with the master data (MD) table.
- To learn about basic entities, go to
SA_NICKNAME.
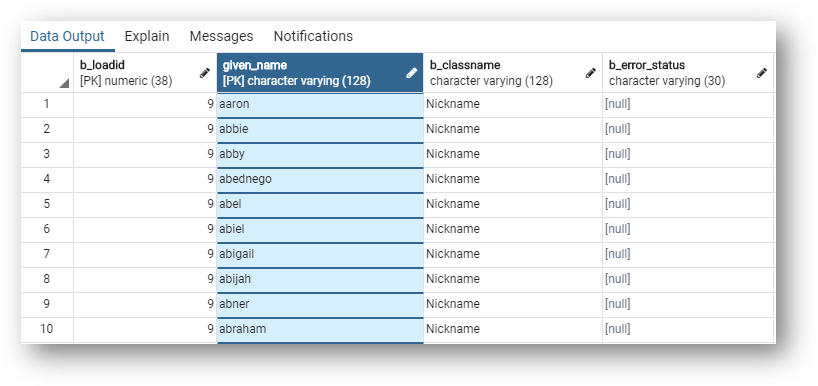
- Note that all source data tables (
SDandSAfor basic entities) have a load ID to identify the load job. - The given name is used as the records' ID (primary key) for the Nickname basic entity.
- Now go to
sa_product, another basic entity.
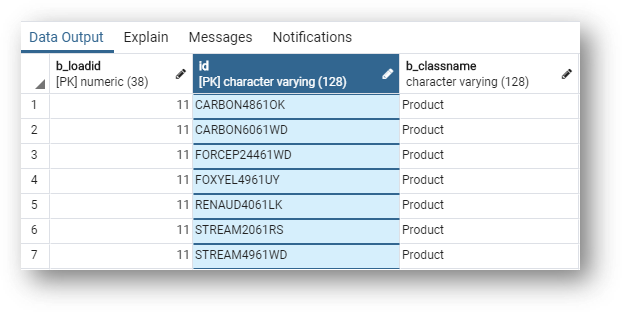
SA_PRODUCT uses the default ID physical name for its primary key. The product ID in this table remains the same as in the golden data GD_PRODUCT table.
We will now see how the basic entity primary key is configured in Semarchy xDM Application Builder.
- Open the CustomerB2CDemo model, right-click on the Nickname entity, and select Alter Entity.
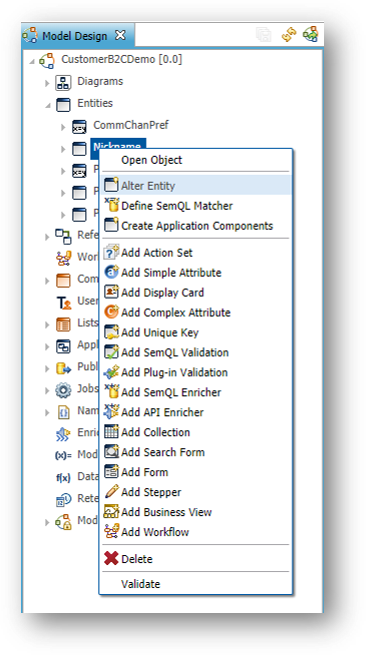
- Click Next.
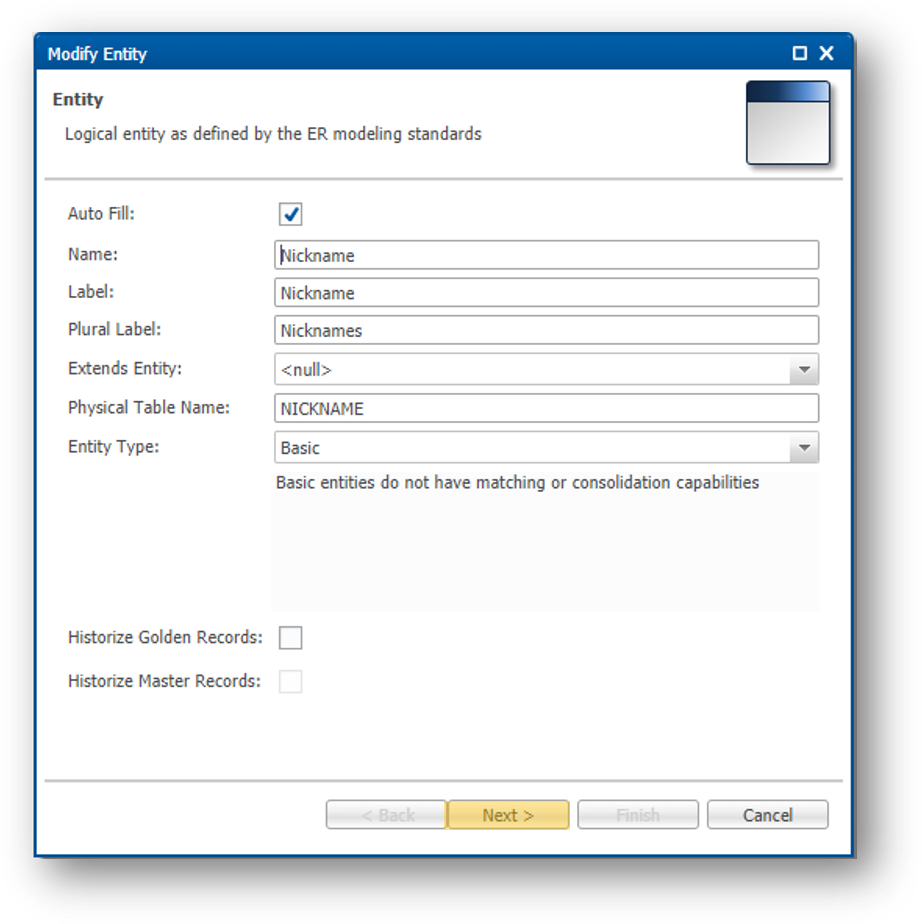
- The next page allows you to set up the primary key for this table.
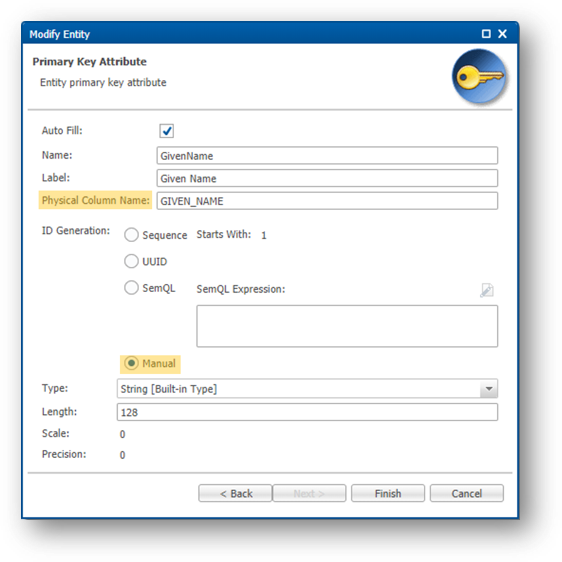
With the Physical Column Name property, you can control the name of the primary key in the database. The Manual option relates to the ID generation method and means that you must load the ID and that you will not rely on xDM to generate it.
- Click on Cancel to quit.
- Edit the Product entity like we just did for Nickname.
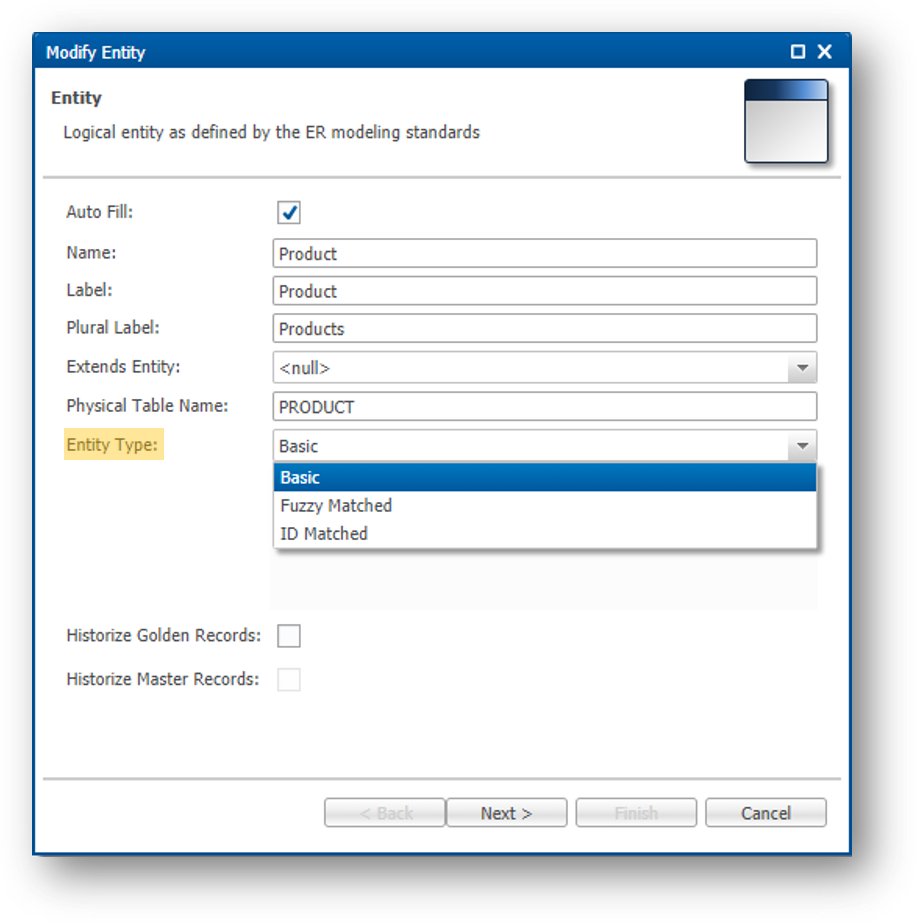
Notice that the entity type (basic, fuzzy-matching, or ID-matching) can be selected on this page and that Product type is a basic entity.
- Press Next to access the primary key settings.
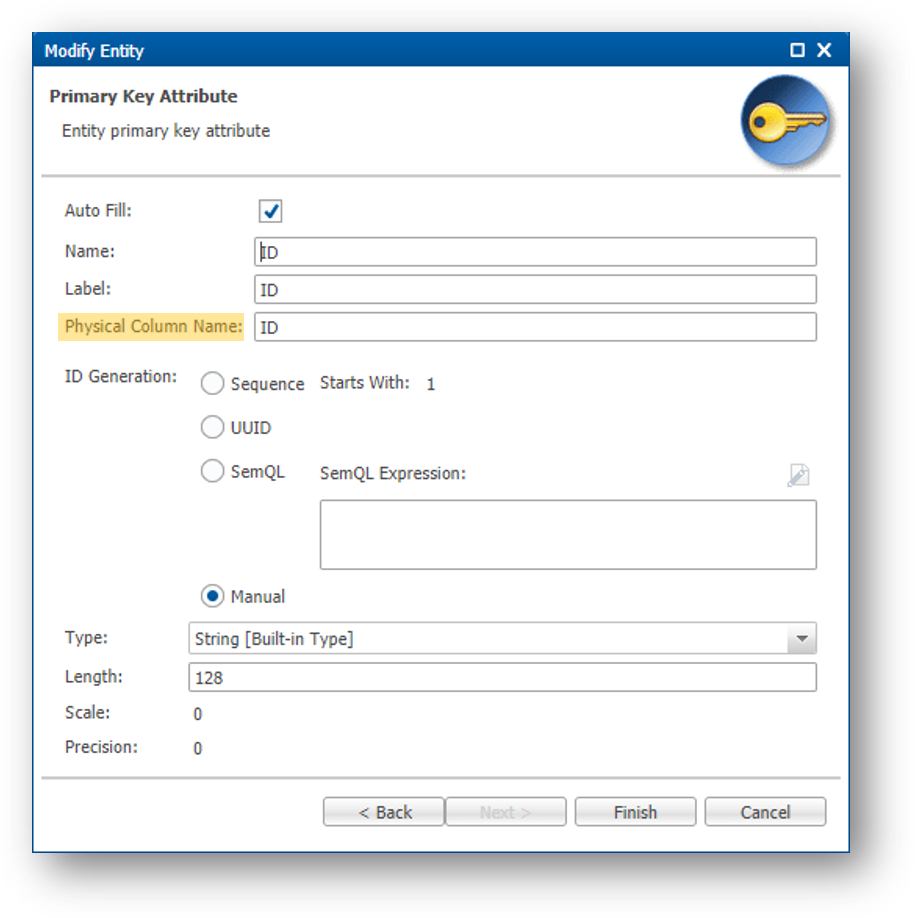
The column name of the primary key for the Product entity is ID (default name).
Also observe that the ID can be entered manually or generated using a sequence, a universal unique identifier (UUID), or a custom rule via a SemQL expression. The ID generation method is selected when the entity is created.
In practice
- Navigate to the Products view under the Browse Data section of the navigation drawer. Product data is modeled using a basic entity.
- Look for the product record with the name "Carbonite Helmet".
- Click on this product to see more information on the Product tab.

- Note the product record's ID: CARBON4861OK.
- Now switch to your SQL client and execute the following query:
select
gd.id golden_id,
gd.product_name golden_product_name,
gd.description golden_desc,
sa.id source_id,
sa.product_name sa_product_name
from sa_product sa
inner join gd_product gd on (
gd.id = sa.id
)
where gd.id='CARBON4861OK' /* Golden ID */
- Observe that
golden_idandsource_idvalues are the same.

The demo data assumes that product IDs are consistent across all systems and, therefore, are suitable for a basic entity. This same ID flows from the source system to the Source Authoring (SA) table and eventually to the Golden Data (GD) table.
Basic foreign keys
In contrast to fuzzy-matching entities, basic entities do not separate the publisher and source IDs, neither at the source nor at the golden record level. Therefore, foreign keys that reference a basic entity use that parent entity's original foreign key.
For example, the SA_PERSON_PRODUCT table references both a fuzzy-matching entity (customer) and a basic entity (product):
FP_PERSONFS_PERSONF_PRODUCT: references the original product ID because the product ID is a universal identifier.
Congratulations!
You have successfully learned the basics about entity types in Semarchy xDM.
Here is a cheat sheet to remind you of the differences between fuzzy-matching, ID-matching, and basic entities:
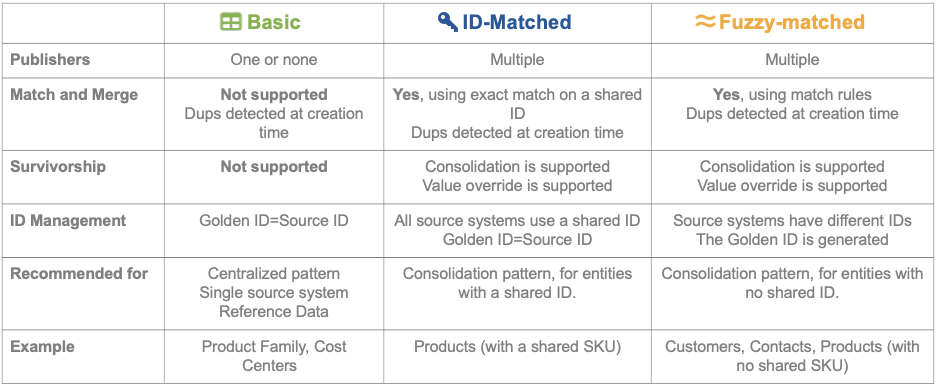
This cheat sheet may come in handy to understand which entity type to use during development time, when you are building your model. It will also help you remember which tables are available and how to use primary keys when you query data from Oracle or PostgreSQL databases.
Next, you will learn to query errors that were raised during the integration process.
Two types of errors can be raised during the integration process:
- Pre-consolidation errors are records that violated constraints before the records went through matching and consolidation. Examples of pre-consolidation errors include missing primary keys, missing mandatory values, and pre-consolidation validation rules.
- Post-consolidation errors occur when constraints are violated (usually post-consolidation validation rules) after the matching and consolidation phases.
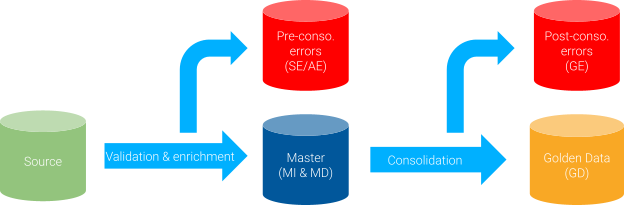
The SE, AE, and GE tables serve as error queues and inform you why records failed integration. xDM saves the name of the constraint in b_constraintname and the type of the constraint in the b_constrainttype columns.
Get all errors on customer records
You can view pre-consolidation errors via the source error (SE) table.
- Run this first query:
select * from se_person;
- Have a look at the results:
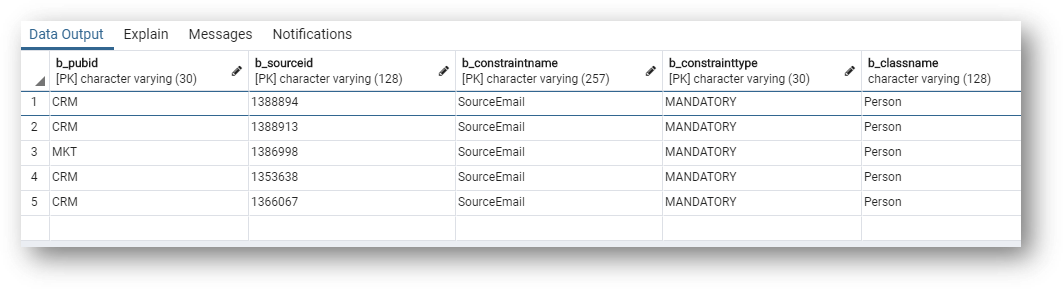
- Notice the error table is minimal. There is no customer information available. Instead, this table contains the identifiers of the source data (SD or SA for basic entities).
b_constraintnameindicates the cause of the error: the records are in the error queue because emails are missing.
- Run this second query and compare the
SE_PERSONview with theSD_PERSON.
select * from sd_person where b_error_status = 'ERROR';
- Notice that this second query shows you that the SD table has a
b_error_statuscolumn, which provides a simple way to detect records with errors.
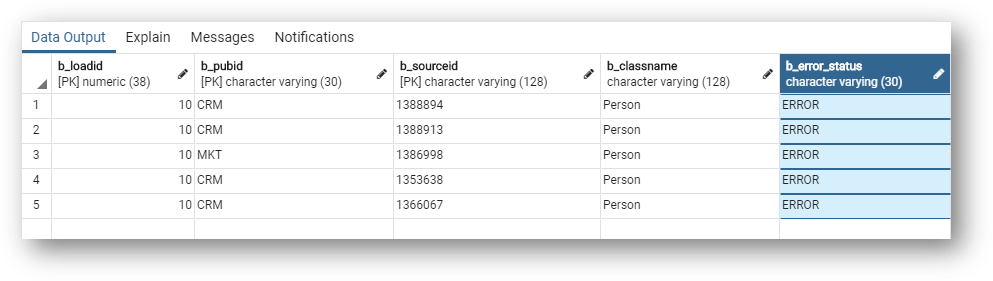
The SD_PERSON table flags records as errors and provides customer information to guide troubleshooting. However, there is no information explaining why the records are in the error queue.
Source data and errors
In this section, you will learn how to join the SE and SD tables to view data, alongside constraint violation.
- Run this query and join
SD_PERSONandSE_PERSONtables to view the reason for errors and the customer information required for troubleshooting.
select
se.b_batchid,
sd.b_loadid,
se.b_constraintname,
se.b_constrainttype,
se.b_pubid,
se.b_sourceid,
sd.first_name,
sd.last_name,
sd.source_email
from se_person se
inner join sd_person sd on (
sd.b_pubid = se.b_pubid
and sd.b_sourceid = se.b_sourceid
and sd.b_loadid = se.b_loadid
)
where sd.b_error_status = 'ERROR';
- Observe the record errors containing data values (from the SD table) and constraint violation details (from the SE table).
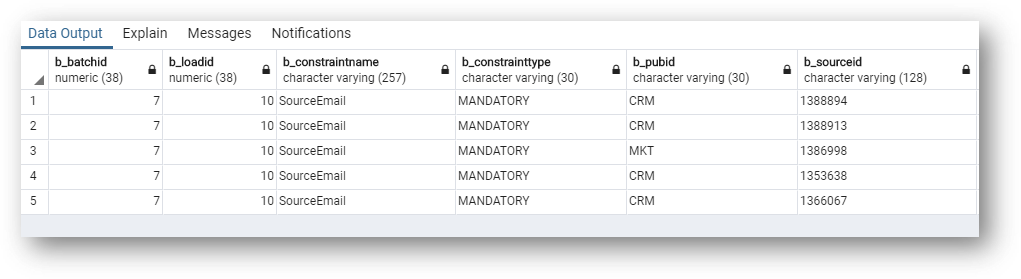
These records are in the error queue due to missing email in the source_email column. A validation rule in the CustomerB2CDemo model requires all customers to have an email address, leading to these records being identified as errors.
You also obtain business-relevant fields to aid troubleshooting.
Congratulations!
You successfully queried xDM to check for errors and their causes using the SQL API.
Great job! You are now familiar with different types of queries that will prove useful in your tasks involving the SQL API.
Learning recap
- You have run basic SQL queries to get customer golden records, as well as master and golden data.
- You have run advanced SQL queries to view customers' data and the products they purchased.
- You can now distinguish fuzzy-matching and basic entities, and understand how each works.
- You have queried error tables and created a useful view to fix errors.
Next steps
In the next unit of the Data Publishing & Consumption track, Load data via SQL, you will learn how to load data in xDM via the SQL API. You will learn basic and advanced loading queries as well as more integration concepts, such as how the integration process works.
To explore other resources, return to the Tutorials menu.
Thank you for completing this tutorial.