| This is documentation for Semarchy xDI 2023.2, which is no longer supported. For more information, see our Global Support and Maintenance Policy. |
Getting Started with Semarchy xDM
Overview
This article explains how to publish data and consume data from a Semarchy xDM data hub.
With this component:
-
You create a metadata for the database schema hosting the Semarchy xDM data location and reverse-engineer the data location tables stored in that schema.
-
You integrate, using mappings, data from and to the data location tables using the templates customized for Semarchy xDM.
-
The Semarchy xDM component also provides specific tools to manage loads, when publishing data to a Semarchy xDM data location.
Connect to your Data
Create a Metadata
To create a metadata for a Semarchy xDM data location:
-
Start the metadata creation wizard, and then select the database technology (Oracle, SQL Server, PostgreSQL, or Microsoft Azure SQL) hosting the Semarchy xDM data location.
-
Enter the database instance connection details and credentials, and then click Connect.
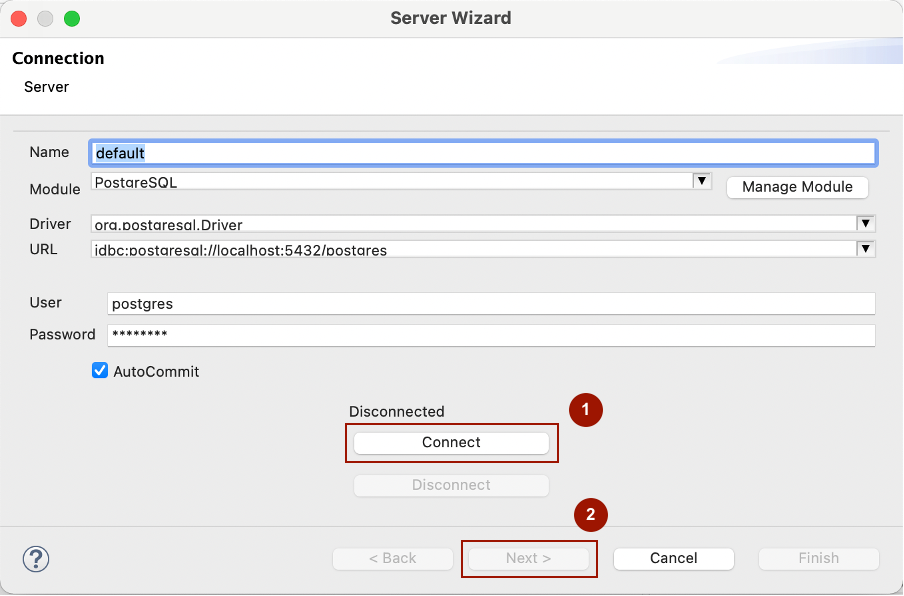
-
On the next page, on the Catalog Name, click Refresh, then select the name of your database from the list.
-
On Schema Name, click Refresh and select from the list the schema containing the Semarchy xDM data location.
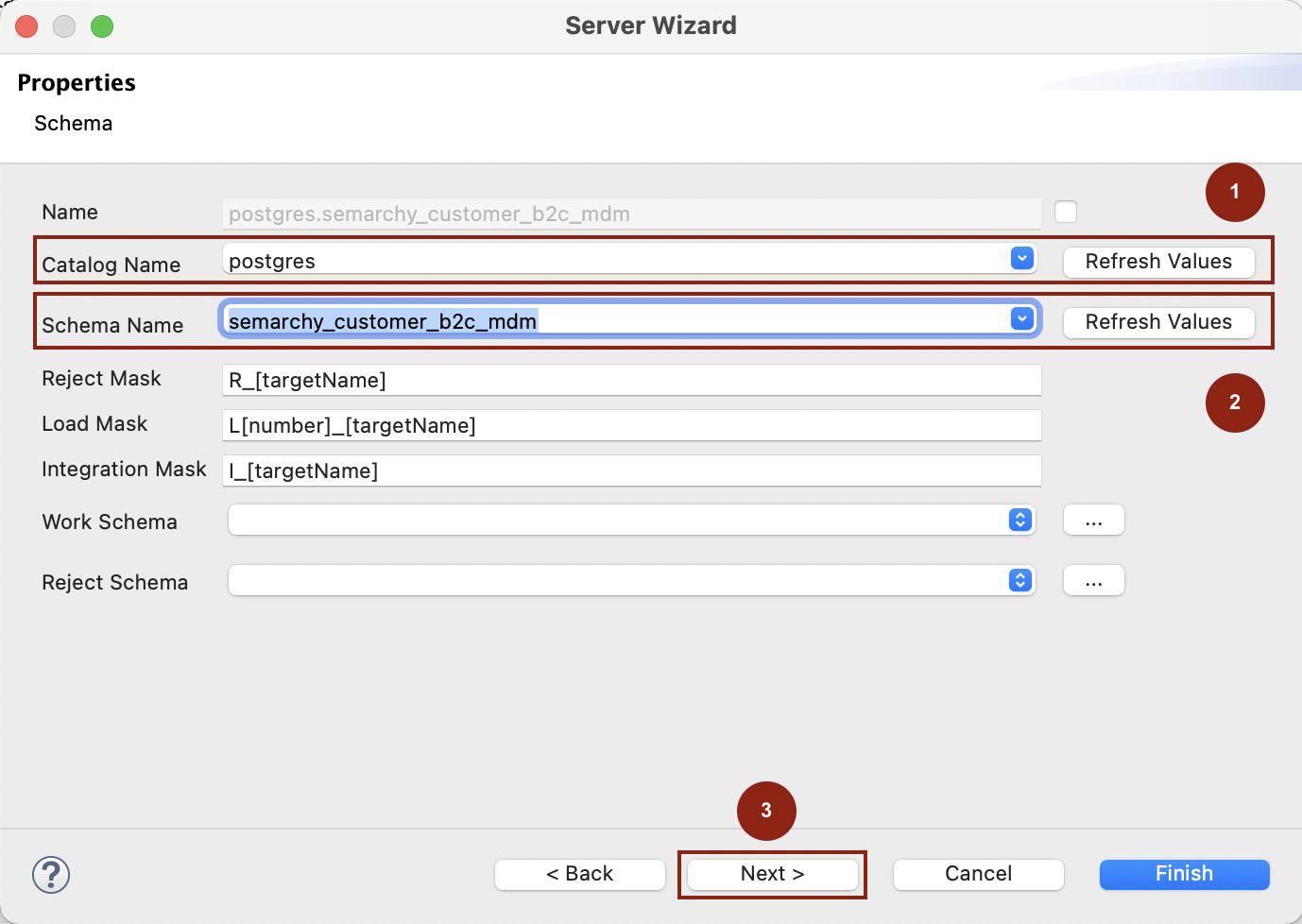
-
Click Next, refresh the list of tables, and select those to reverse-engineer.
-
Click Finish. The tables are reverse-engineered in the metadata.
Define the xDM Parameters
The xDM parameters defined in the metadata configure the default Load ID management behavior for mappings targeting tables in this metadata and using the INTEGRATION Semarchy xDM template.
These parameters can be found in the xDM finger tab of the server node of the RDBMS metadata (Oracle, SQL Server, PostgreSQL, or Microsoft Azure SQL).
| Parameter | Description |
|---|---|
Is xDM Database |
Defines whether the current metadata hosts an xDM data location. When this option is selected, the INTEGRATION Semarchy xDM template becomes available when targeting tables in the metadata, and uses by default the xDM parameters defined of the metadata. |
Default Load ID Management |
Defines how templates manage Load IDs. Possible options are:
|
Default Load ID Type |
This property only applies when the load ID management is set to Autonomous. Defines where the INTEGRATION Semarchy xDM template should get the load ID from:
|
Default Continuous Load Name |
Name of the default Continuous Load to use, when Default Load ID Type is set to Continuous Load ID. By default, this field is set to |
Default xDM User Name |
Name of the user initializing and submitting the load. |
Default Repository Schema Name |
Name of the database schema hosting the Semarchy xDM repository. |
Default Data Location Name |
Name of the data location hosting the data hub. You can find the name of the data location Semarchy Data Location view. |
Default Data Location Schema |
Name of the database schema hosting the Semarchy xDM data location tables. |
Default Integration Job Name |
Default Integration Job Name used when submitting a Load. |
| The xDM Parameters define default values used by the mappings. You can override them in each mapping by setting the corresponding template parameters. |
Create your mappings
This section explains how to create mappings with Semarchy xDM tables, to extract data from and load data to Semarchy xDM data hubs.
Extract data from MD and GD tables
The data location’s golden data (GD) and master data (MD) tables are commonly used to consume records from the data location. To extract data from Semarchy xDM, use these tables as sources in your mappings.
| Refer to Consume Data Using SQL in the Semarchy xDM documentation for more information about the patterns to consume master and golden data from Semarchy xDM. |
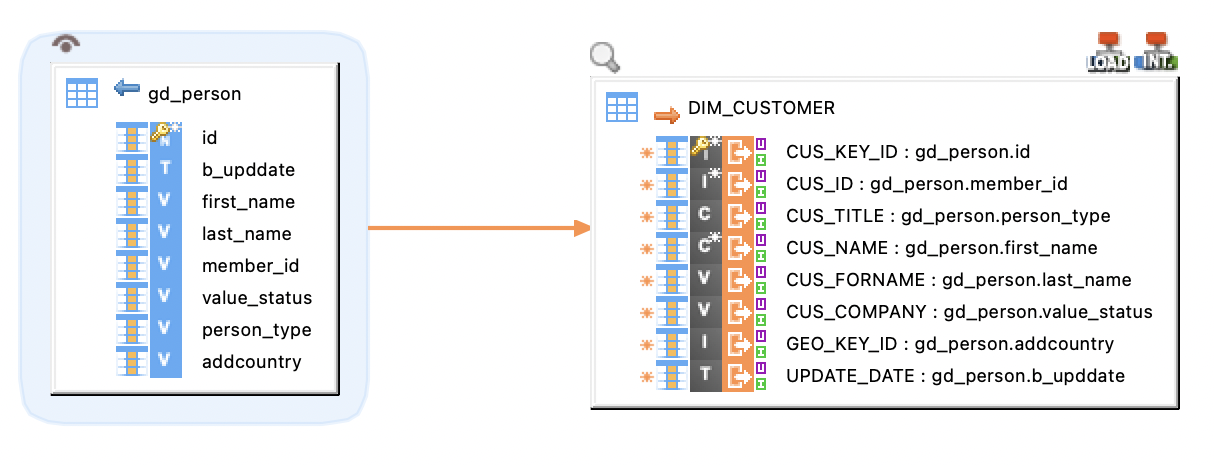
Load data into SD and SA tables
The Source Authoring (SA) and Source Data (SD) tables are used to load data into the data location. To load data to Semarchy xDM, use these tables as targets in your mappings.
| Refer to Publish Data Using SQL for more information about loading data into Semarchy xDM using the SD and SA tables. |
|
When designing mappings targetting Semarchy xDM:
|
When loading data into the SD or SA tables of a data location, you must populate the business data columns according to your data flow requirements. You must also map the following columns:
-
B_CLASSNAME: Map this column with a literal value or a column containing the name of the entity that you want to load. -
B_PUBID: For fuzzy and ID-matched entities, map this column to a literal value or a column containing the code of the publisher on behalf of whom you are publishing the data. -
ID column: The ID column to map depends on the type of entity:
-
For Basic entities: Column representing the primary key attribute for the entity.
-
For ID-matched entities: Column representing the primary key attribute for the entity.
-
For Fuzzy matched entities: If the entity uses fuzzy matching, then load the value of the primary key coming from the source system into the
B_SOURCEIDcolumn. If this primary key is composite, concatenate the values of the composite primary key and load them in theB_SOURCEIDcolumn.
-
-
Reference columns: When loading data for entities that are related by a reference relationship, load the referencing entity with the value of the referenced primary key. The columns to load (F_, FS_, and FP_ columns) depend on the entity type of the referenced entity: for more details, refer to the Publish Data > References in the Semarchy xDM documentation.
Manage Load IDs
Records loaded to Semarchy xDM are batched in a Load ID. The Integration Semarchy xDM template supports both automatic and user-managed load IDs.
There are two methods to manage the Load ID:
-
Autonomous: In this mode, Semarchy xDI automatically manages and populates the Load ID with the data. Semarchy xDI generates a Load ID (or retrieves it from a continuous load), uses it while loading the data, and submits or cancels the load it has generated depending on the mapping outcome. This mode is used by default.
-
User-Managed: In this mode, you generate/retrieve the Load ID separately from the mappings, and decide when to submit or cancel. Dedicated Semarchy xDM Tools are available to perform these operations. This is typically useful when you want full control over the load lifecycle. For example, when you want to use the same generated Load ID for multiple mappings.
Two types of Load IDs can be used:
-
Continuous Load ID: Retreives the ID of an existing Semarchy xDM Continous Load. Data loaded using a continuous load is automatically processed on the continuous load’s schedule, using a job defined in the continuous load. You do not need to submit such a load, and cannot cancel it.
-
Standalone Load ID: A Load ID is generated and stored in a variable. Such a load needs to be explicitly submitted after the data is loaded, or canceled.
| You can configure the default mapping behavior in the metadata’s xDM parameters. You can override these values per mappings using the corresponding template parameters. |
| Refer to Publish Data Using SQL for more information on publishing data into Semarchy xDM. |
Autonomous Load ID
To use Autonomous Load ID management:
-
Create a mapping with Semarchy xDM as a target.
-
Choose the Autonomous Load ID management, either in the Semarchy xDM metadata’s Default Load ID Management property (default behavior), or in the Load ID Management template property.
-
Map your columns, as explained in Load data into SD and SA tables.
-
Run the mapping.
Data is loaded into Semarchy xDM with a Standalone Load ID that is automatically created, used, and submitted for the mapping, or with the specified Continuous Load ID
User-Managed Load ID
To use the User-Managed Load ID management:
-
Create a new process, which will orchestrate data loading with multiple mappings.
-
In this process, create a Get LoadID action to initialize a new Load ID, or retrieve the ID of a continuous load.
-
Create one or multiple mappings, with Semarchy xDM as a target.
In these mappings:-
Set Load ID Management to User-Managed, or leave it blank if this default value is set in the target metadata.
-
Map your columns, as explained in Load data into SD and SA tables.
-
Add these mappings to the process.
-
-
If you use a Standalone Load ID, add to the process Submit Load and Cancel Load actions after the mappings to submit or cancel load, depending on the mappings success or failure.
NOTE: If you use a Continuous Load ID, you do not need to submit. -
Run the process.
Data is loaded into Semarchy xDM with the user-managed Load ID.
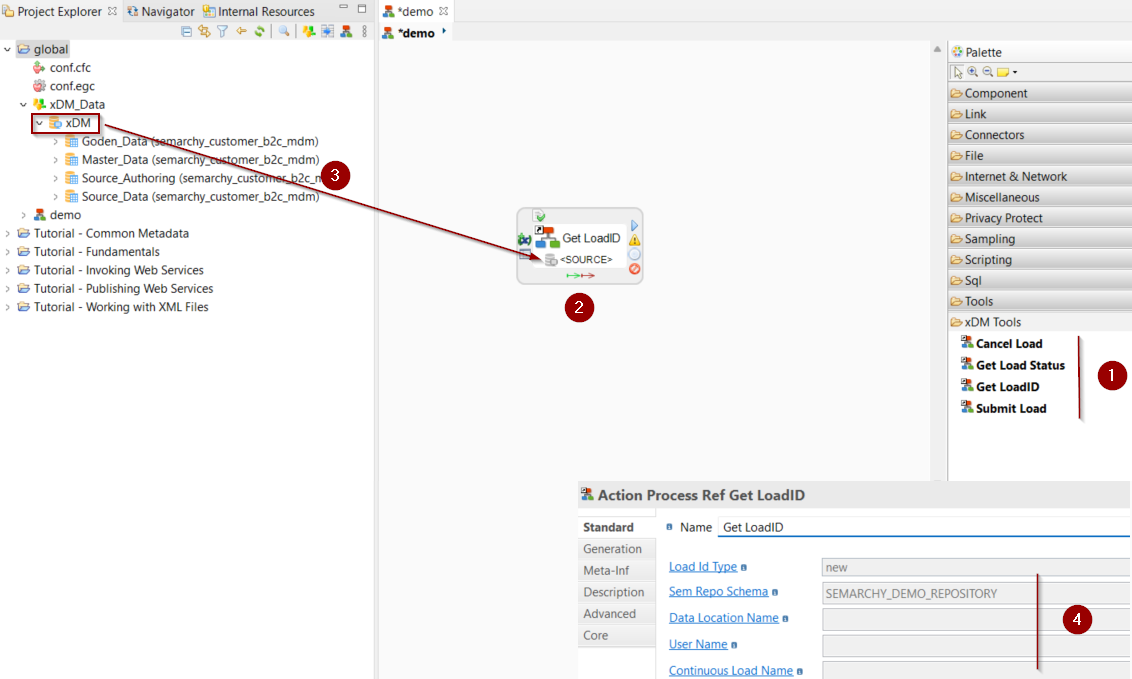
The following image illustrates a process for loading data into a source data table with the user-managed Load ID management:
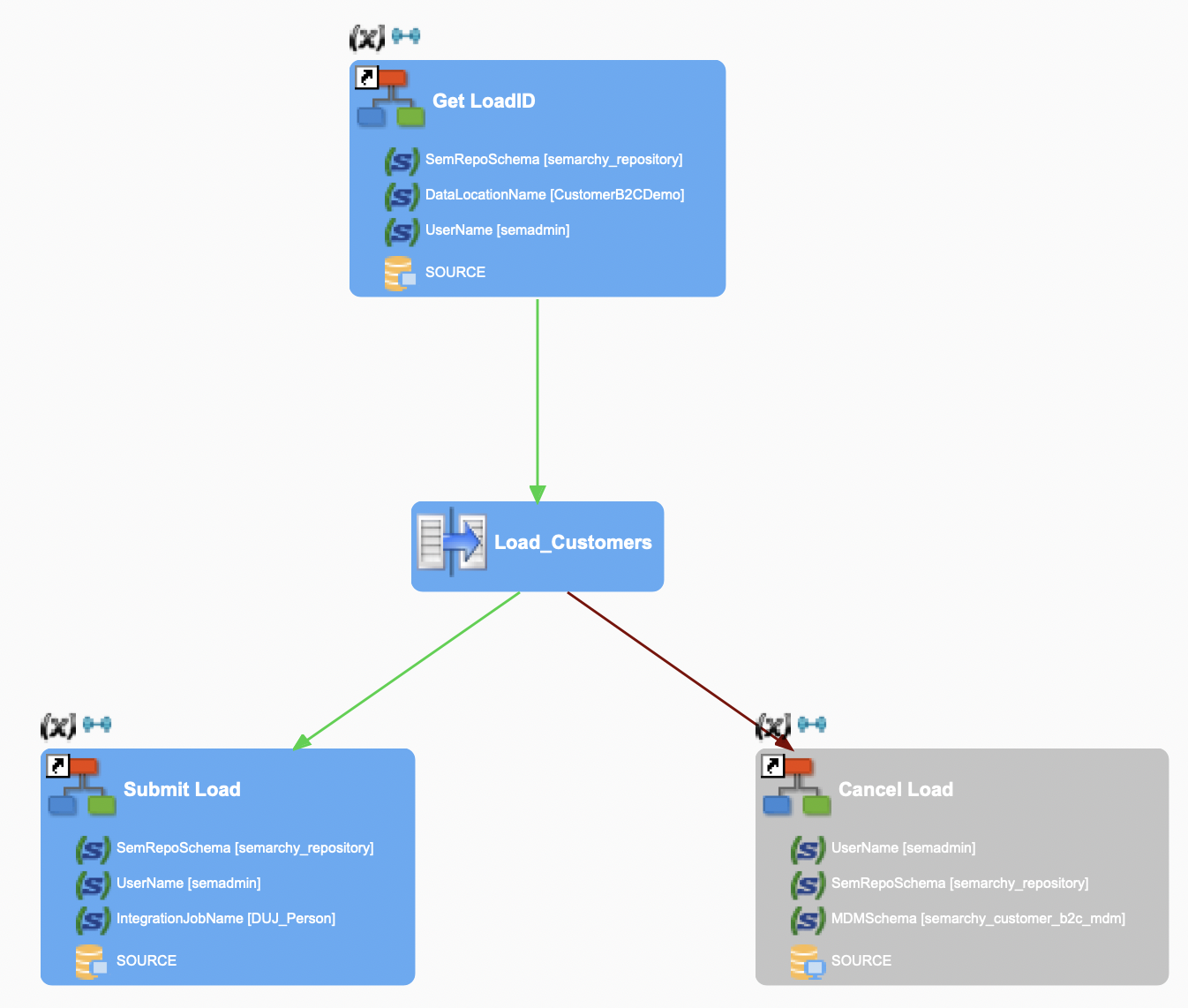
Semarchy xDM Tools
The Semarchy xDM component provides dedicated tools for load management operations, as required when publishing data in a Semarchy xDM data location with User-Managed Load IDs. These tools can be used as actions in processes.
The following tools are available:
-
Get LoadID initializes a new load or retrieves a continuous load, and stores the resulting Load ID in a variable.
-
Submit Load submits a load, whose ID is read from a variable.
-
Cancel Load submits a load, whose ID is read from a variable.
-
Get Load Status gets the progress of a load after a submit.
To add a Semarchy xDM Action to a process:
-
Select the appropriate tool from Palette > xDM Tools.
-
Click the process background to add it.
-
Drag and drop the database containing the Semarchy xDM repository onto the
SOURCEMetadata Link placeholder.Make sure to drag and drop on the SOURCEmetadata link a metadata representing the Semarchy xDM repository. Depending on the implementation of Semarchy xDM, this database may or may not be the same database as the one containing the data location. -
Fill in the parameters of the tool. See the Actions Reference for the complete list of parameters for each tool.
Example: