| This is documentation for Semarchy xDI 2023.3, which is no longer supported. For more information, see our Global Support and Maintenance Policy. |
Getting Started with Apache Kafka Raw Metadata
Overview
This article describes how to read and write raw data with Apache Kafka. The Semarchy xDI raw metadata allows exchanging data with no specific format.
To exchange data in a specific format (AVRO or JSON), you need to use the Semarchy xDI structured metadata. Refer to Getting Started with Kafka Structured Metadata for more information.
Create metadata
To create the metadata:
-
Right-click the project folder, then select New > Metadata.
-
In the New Metadata window, select Kafka Server - raw and click Next.
-
Name the data model and click Next.
-
Select the installed Apache Kafka module and click Finish.
The metadata is created.
Define the server properties
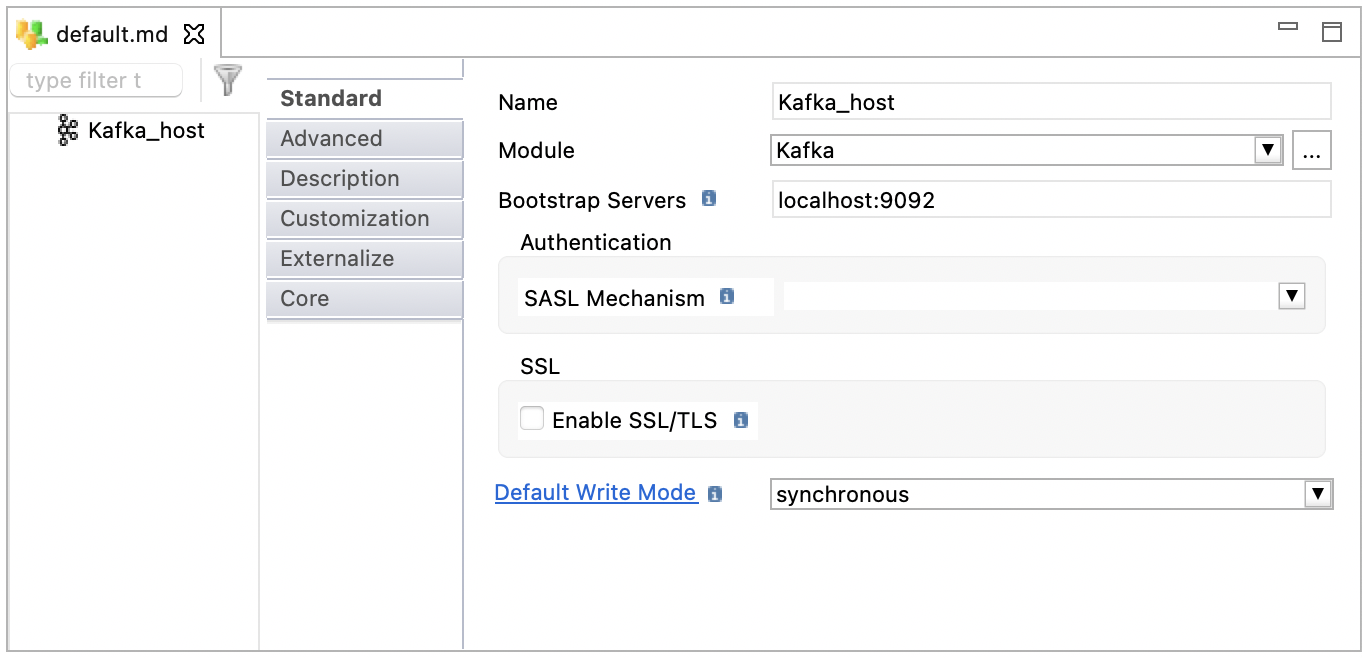
Select the root node of the metadata to define the server properties listed below:
| Property | Description |
|---|---|
Name |
A label/alias for this metadata. |
Module |
Apache Kafka module to use. |
Bootstrap Servers |
Corresponds to the |
SASL Mechanism |
SASL mechanism to connect to Apache Kafka. Leave blank to use the Apache Kafka client’s default settings. The following options are available:
|
Enable SSL/TLS |
Enables a secured connection between the client and the broker. Leave blank to use the Apache Kafka client’s default settings. |
Default Write Mode |
Defines the default value for the
|
The following image illustrates an example of a Apache Kafka host configuration:
Define topics
Topics are used to store data in Apache Kafka in the form of messages.
To define a topic:
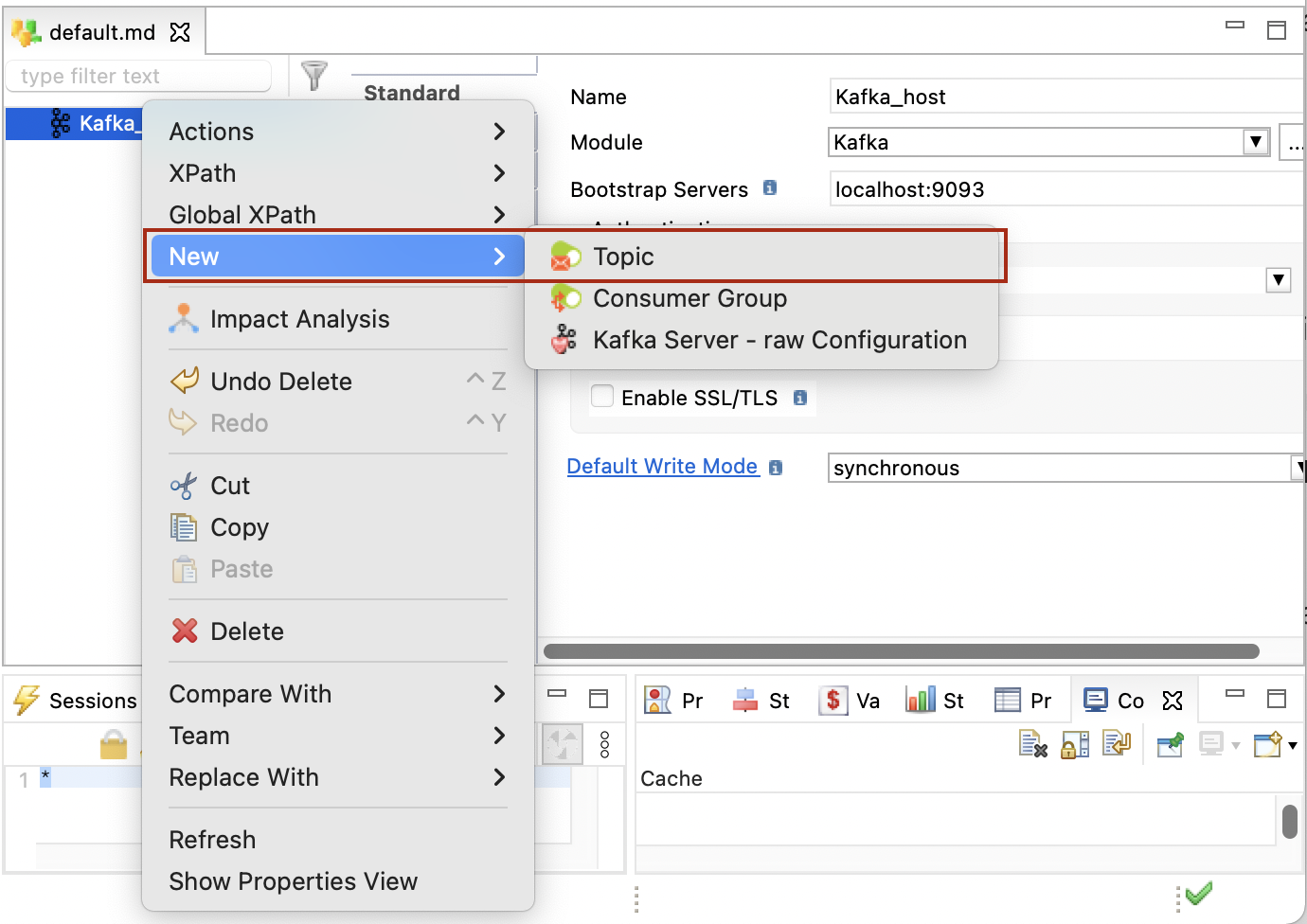
-
Right-click the server node, then click New > Topic.
-
Enter a Name and a Physical Name for the topic. The physical name corresponds to the actual topic name in Kafka.
-
Right-click the topic, click New > Value, to create the value and set its type. The Value node corresponds to the Kafka message payload (Record), which can be used in a mapping.
You must define a single Value node for each topic. 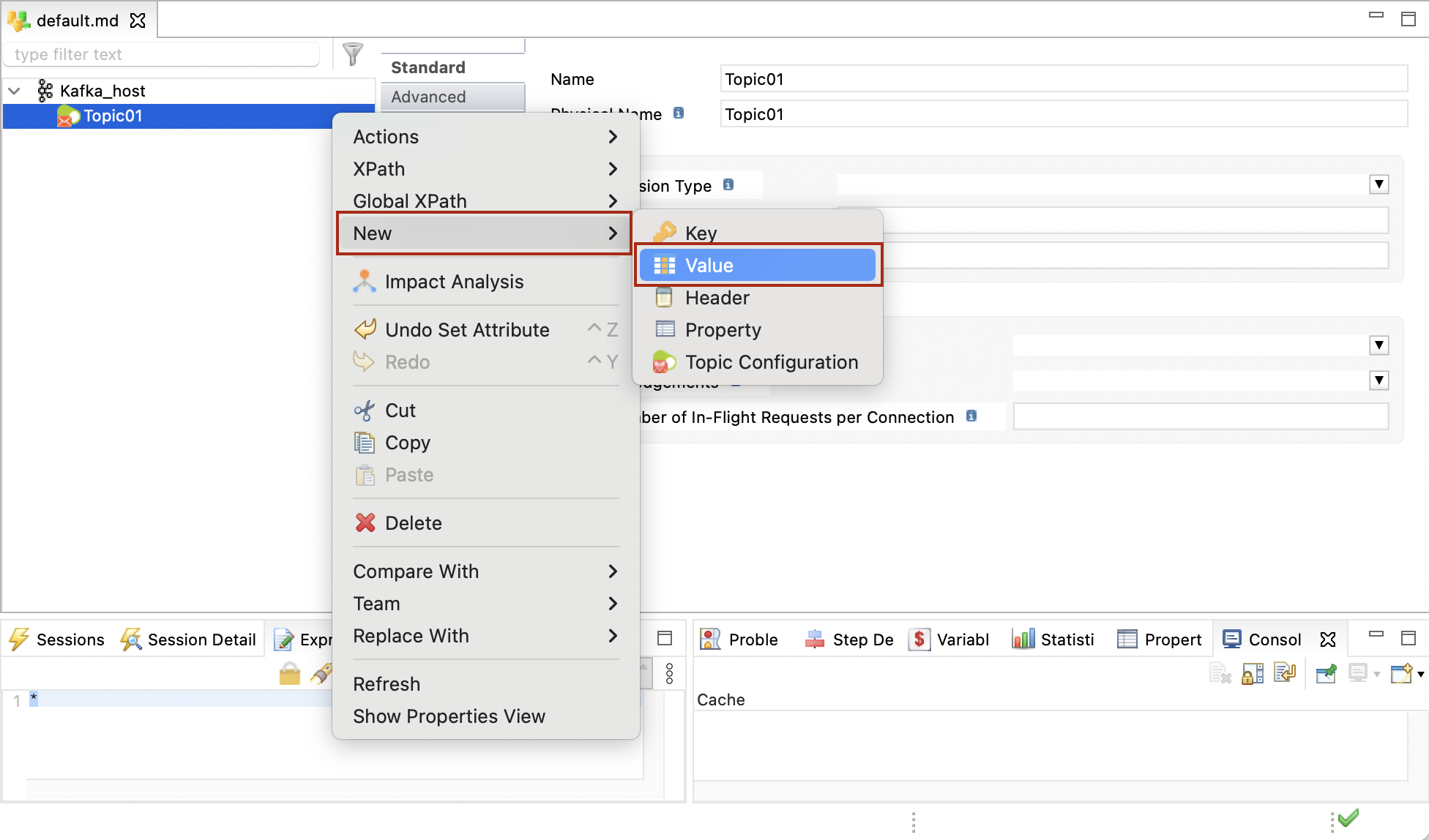
-
Optionally add Key, Header, or Property nodes.
These nodes correspond to the Kafka message headers, properties, and keys. They can be used in mappings that produce messages on the Kafka topic.-
Key: A Key can be attached to the message produced on a topic. When this node is not defined, or not mapped in a mapping, no key is written.
A topic may contain a single Key node. -
Header: Headers are attached to the message when writing into the topic. You can add as many header nodes as required.
-
Property: An additional property is attached to the messages in the topic.
-
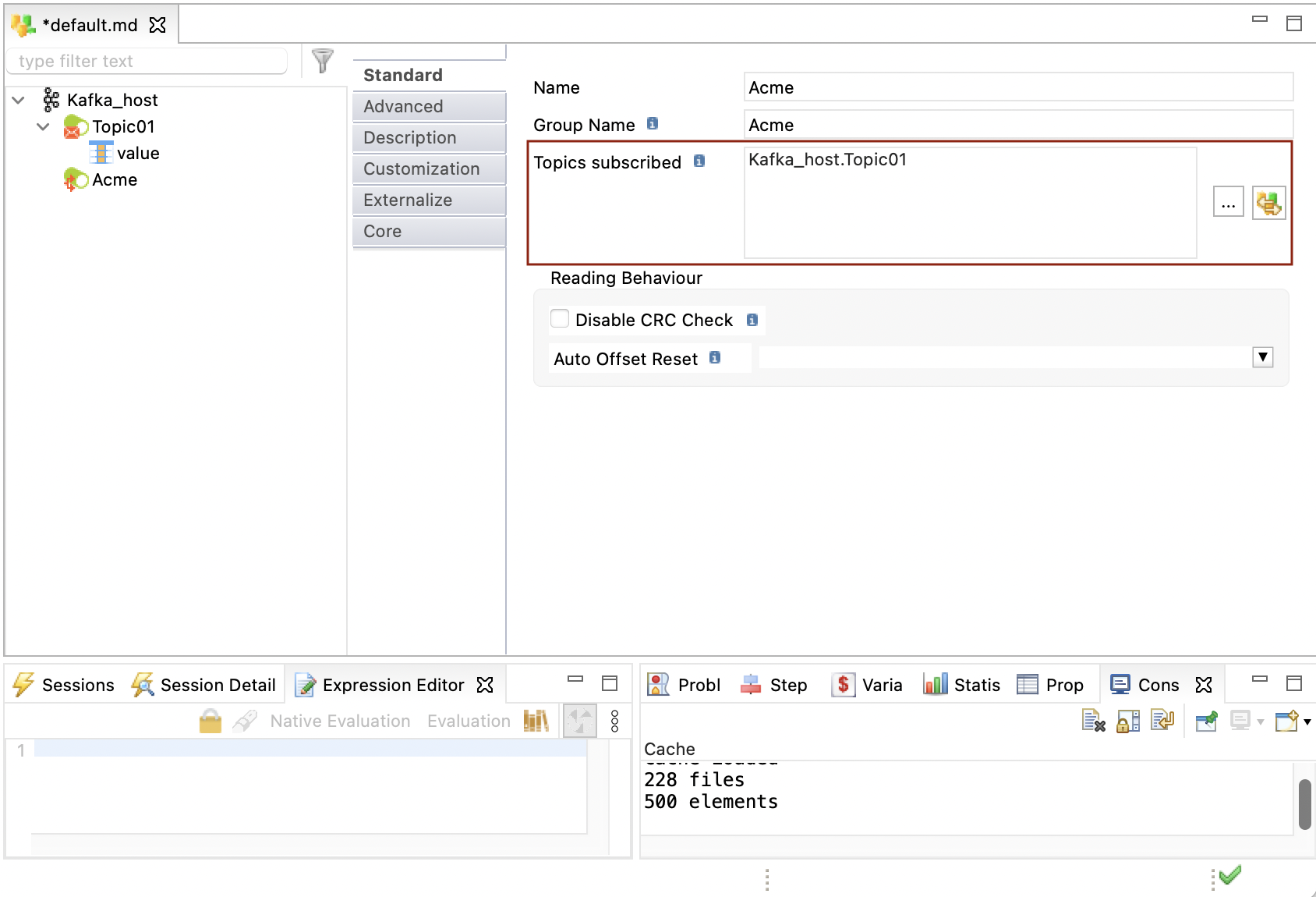
Define consumers
Consumers subscribe to topics to read messages.
To define a consumer:
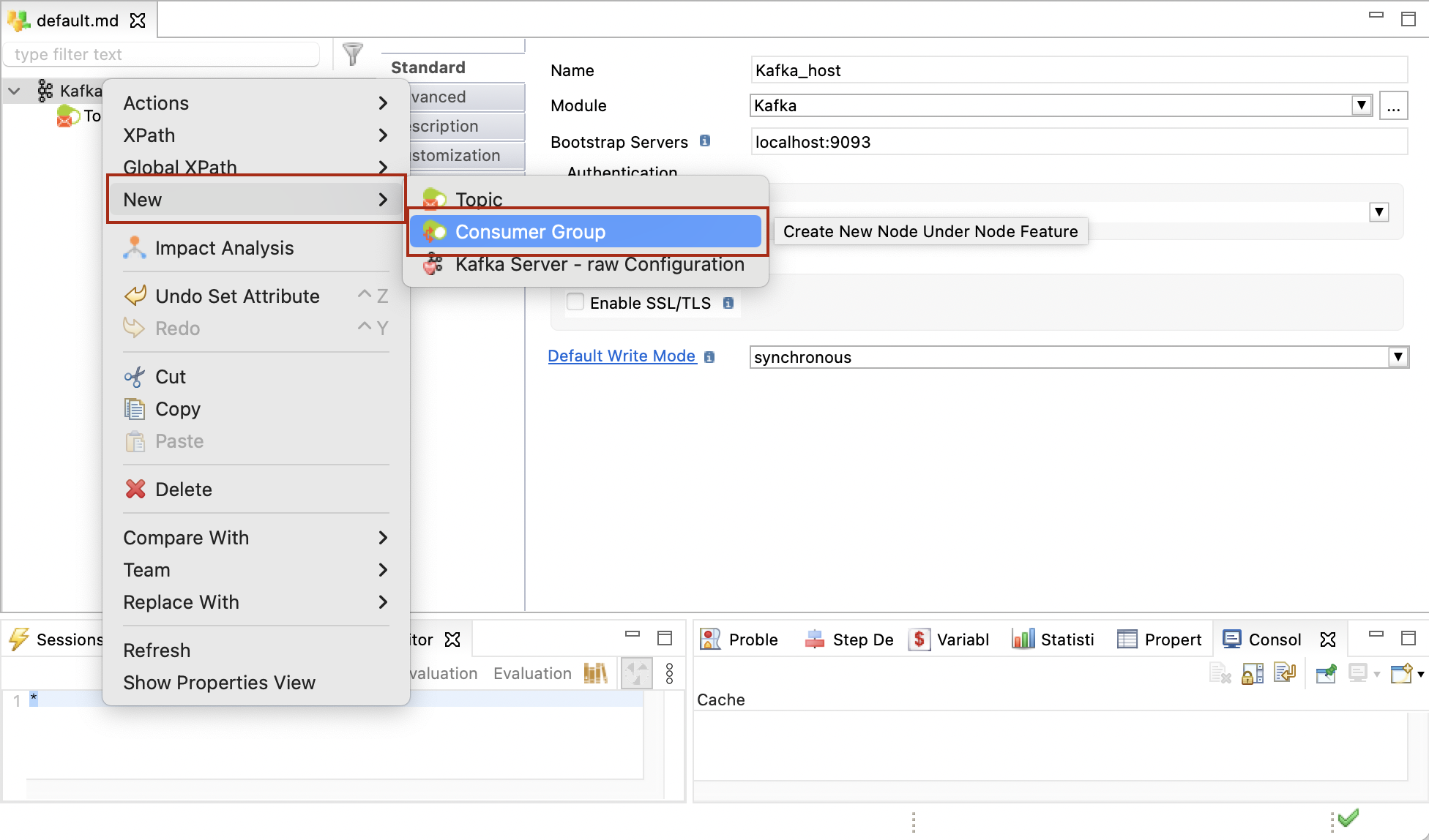
-
Right-click the host, then click New > Consumer Group.
-
Enter a name and a physical name for the consumer.
-
In the Topics subscribed field, add the topics to which the consumer should subscribe.
-
Right-click the consumer, click New > Value, and set its type. The Value node corresponds to the Kafka message payload (Record) consumed from the topic.
You must define a single Value node for each consumer. 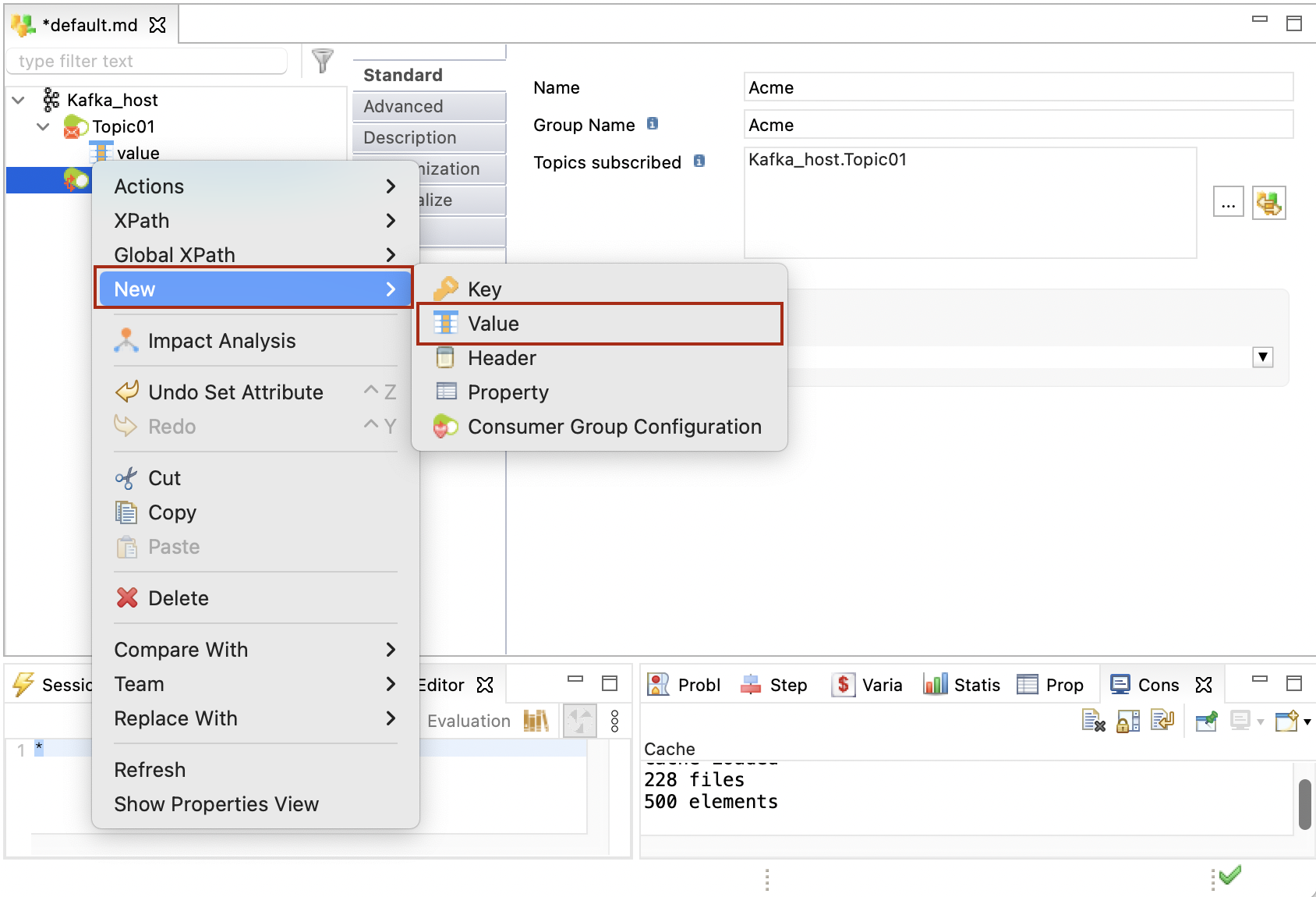
-
Add Key, Header, and Property nodes similarly to a topic definition. These fields are retrieved when consuming from the subscribed topics and can be used in mappings.
Create mappings
Mappings can be created for sending to (producer) and receiving (consumer) data from Kafka.
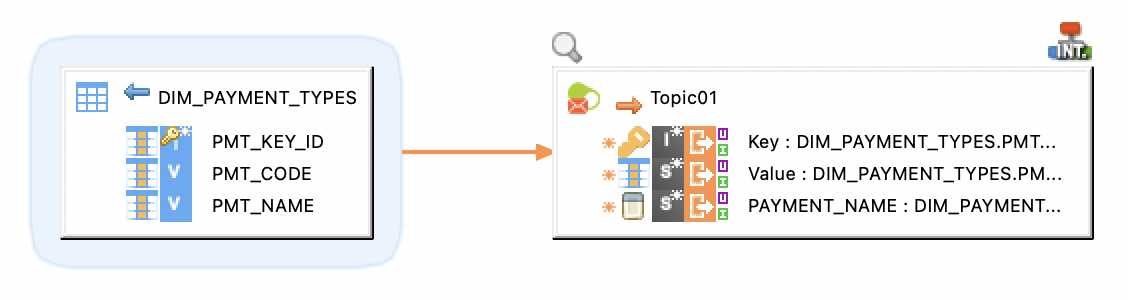
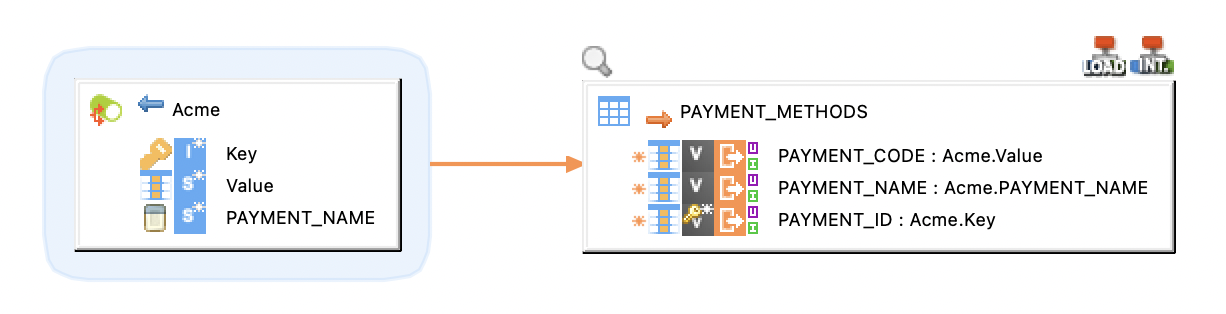
Producer Mapping
The following example illustrates a producer mapping in which a topic is used as a target. This mapping loads the Key and Value (message payload) from the database table and produces messages to the topic.
Sample Project
The Apache Kafka Component ships sample project(s) that contain various examples and use cases.
You can have a look at these projects to find samples and examples describing how to use it.
Refer to Install Components to learn how to import sample projects.