Getting started with Apache Kafka Raw metadata
Overview
This article describes how to read and write raw data with Apache Kafka. The Semarchy xDI raw metadata exchanges data with no specific format.
To exchange data in AVRO or JSON format specifically, use the Semarchy xDI structured metadata. Refer to Getting started with Kafka Structured metadata for more information.
Create metadata
To create the metadata:
-
Right-click the project folder, then select New > Metadata.
-
In the New Metadata window, select Kafka Server - raw and click Next.
-
Name the data model and click Next.
-
Select the installed Apache Kafka module, and click Finish to create the metadata.
Define the server properties
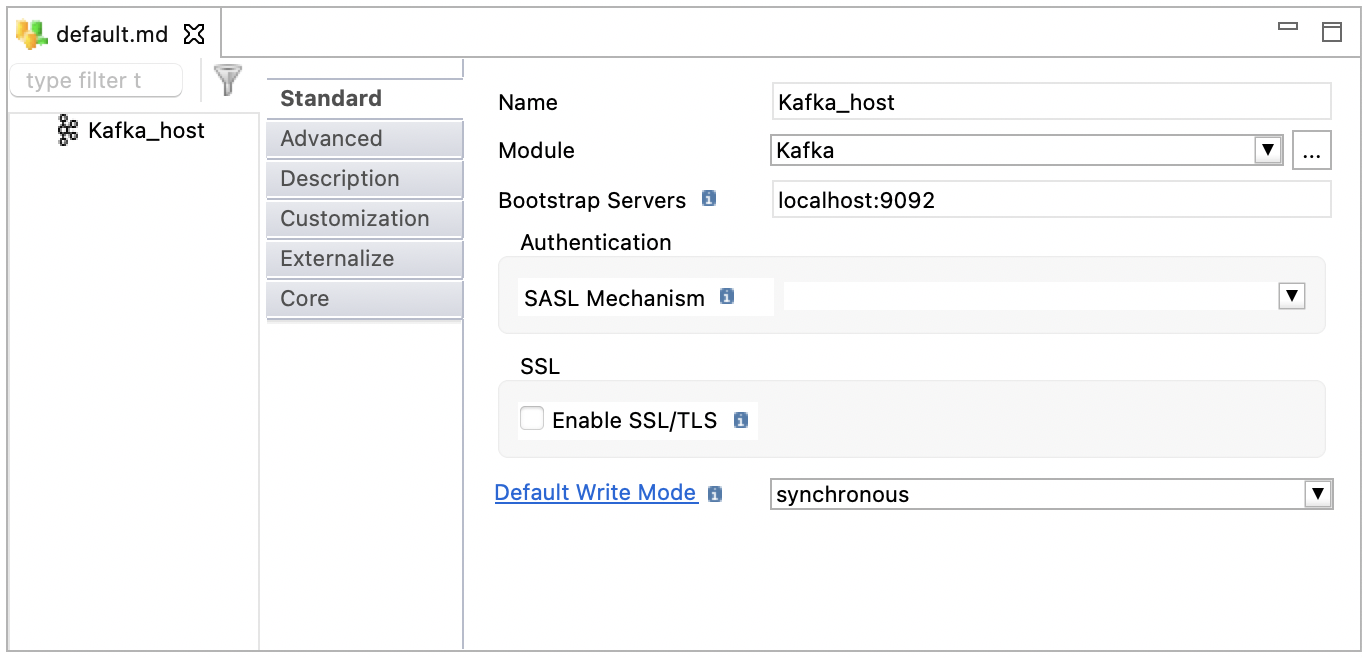
Select the root node of the metadata object to define the following server properties:
| Property | Description |
|---|---|
Name |
A label/alias for this metadata. |
Module |
Apache Kafka module to use. |
Bootstrap Servers |
Comma-separated list of bootstrap servers in the |
SASL Mechanism |
SASL mechanism to connect to Apache Kafka. Leave blank to use the default Apache Kafka client settings. For available SASL configurations and their fields, read the SASL options table. |
Enable SSL/TLS |
Enables a secured connection between the client and the broker. Leave blank to use the default Apache Kafka client settings. For available SSL/TLS options, read the SSL/TLS options table. |
Default Write Mode |
Defines the default value for the
|
When you choose a SASL mechanism, xDI Designer displays further options.
Read the official Kafka documentation for more information about SASL mechanisms.
Mechanism |
Options |
GSSAPI |
Enables GSSAPI/Kerberos authentication. Set the following two new options:
|
PLAIN |
Plain authentication. Set a username and password. |
SCRAM-SHA-256 |
SCRAM-SHA-256 authentication. Set a username and password. |
SCRAM-SHA-512 |
SCRAM-SHA-512 authentication. Set a username and password. |
When you enable SSL/TLS, xDI Designer displays further options. Blank fields use the default Apache Kafka settings.
Read the official Kafka documentation for more information about SSL/TLS options.
| Property | Description |
|---|---|
Protocol |
Secure protocol to use for the connection. |
Key Password |
Password of the private key in the keystore file. |
Key Store Type |
Keystore file type, such as JKS. |
Key Store Location |
Full path to the keystore file that the runtime needs to access. |
Key Store Password |
Password of the keystore file. |
Trust Store Type |
Truststore file type, such as JKS. |
Trust Store Location |
Full path to the truststore file that the runtime needs to access. |
Trust Store Password |
Password of the truststore file. |
Enabled Protocols |
Which secure protocols to enable when communicating with the broker. |
Define topics
Topics are used to store data in Apache Kafka in the form of messages.
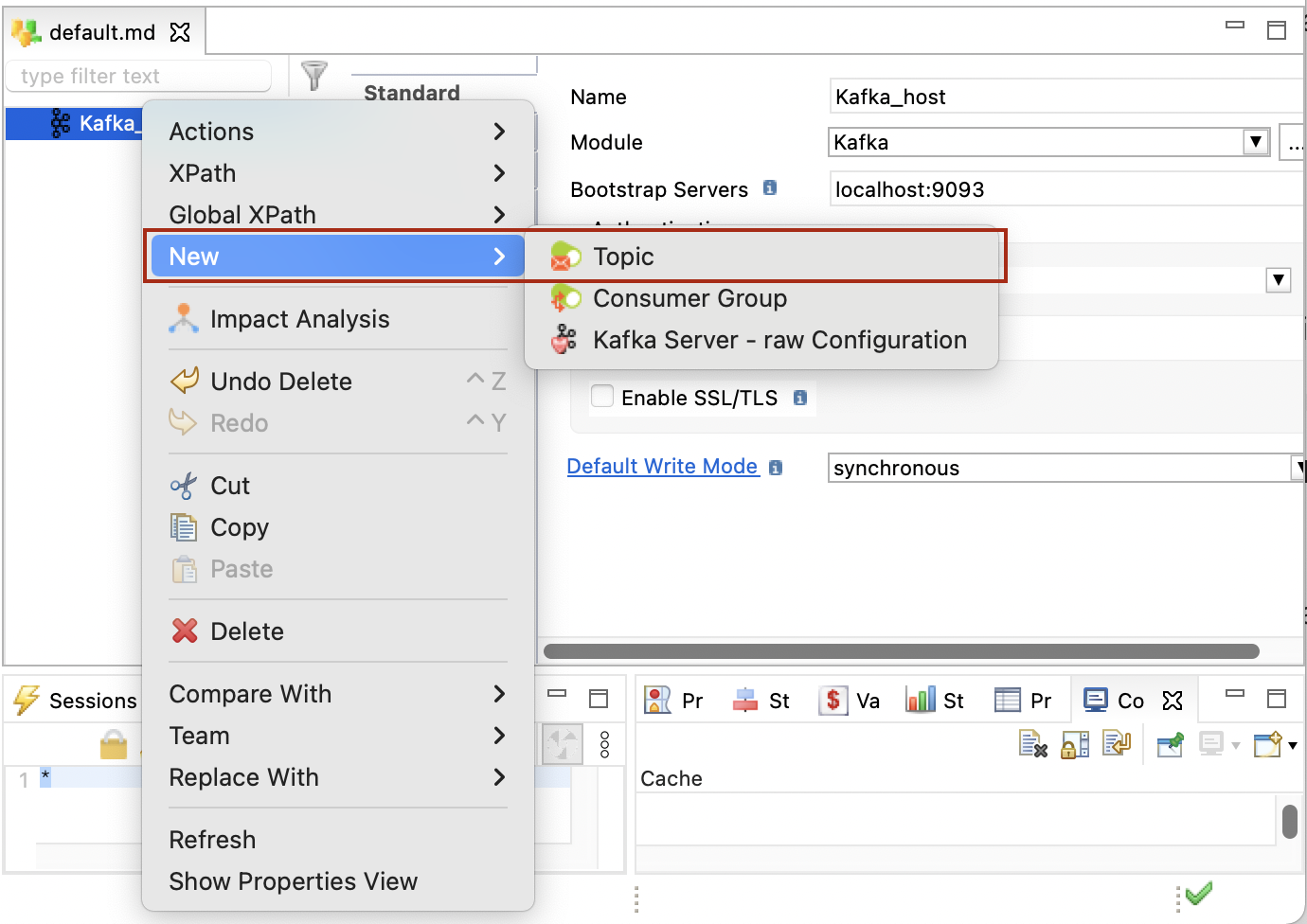
To define a topic:
-
Right-click the server node, then click New > Topic.
-
Enter a Name and a Physical Name for the topic. The physical name corresponds to the actual topic name in Kafka.
-
Right-click the topic, click New > Value, to create the value and set its type. The Value node corresponds to the Kafka message payload (Record), which can be used in a mapping.
You must define a single Value node for each topic. 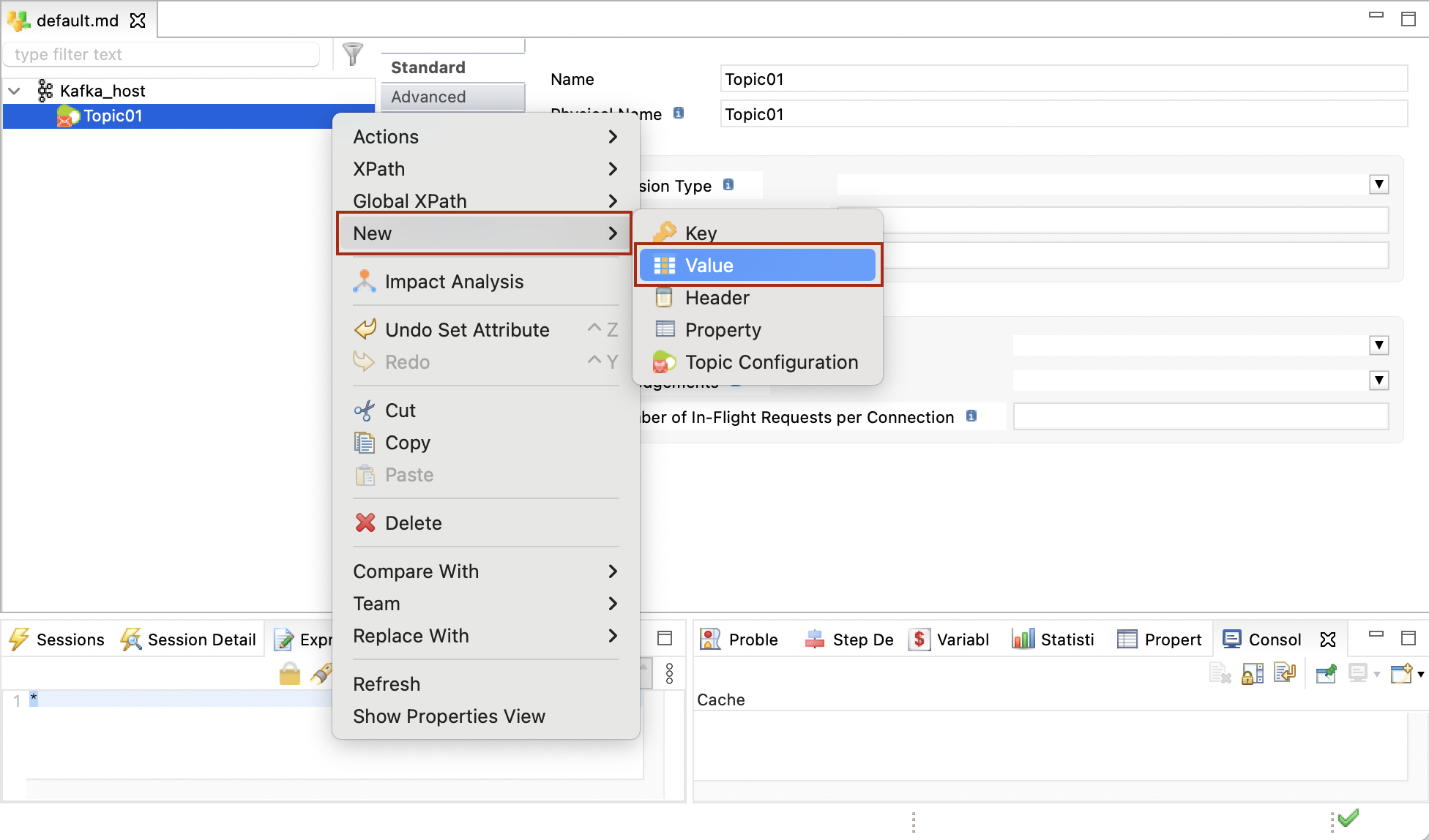
-
Optionally add Key, Header, or Property nodes.
These nodes correspond to the Kafka message headers, properties, and keys. They can be used in mappings that produce messages on the Kafka topic.-
Key: A Key can be attached to the message produced on a topic. When this node is not defined, or not mapped in a mapping, no key is written.
A topic may contain a single Key node. -
Header: Headers are attached to the message when writing into the topic. You can add as many header nodes as required.
-
Property: An additional property is attached to the messages in the topic.
-
Define consumers
Consumers subscribe to topics to read messages.
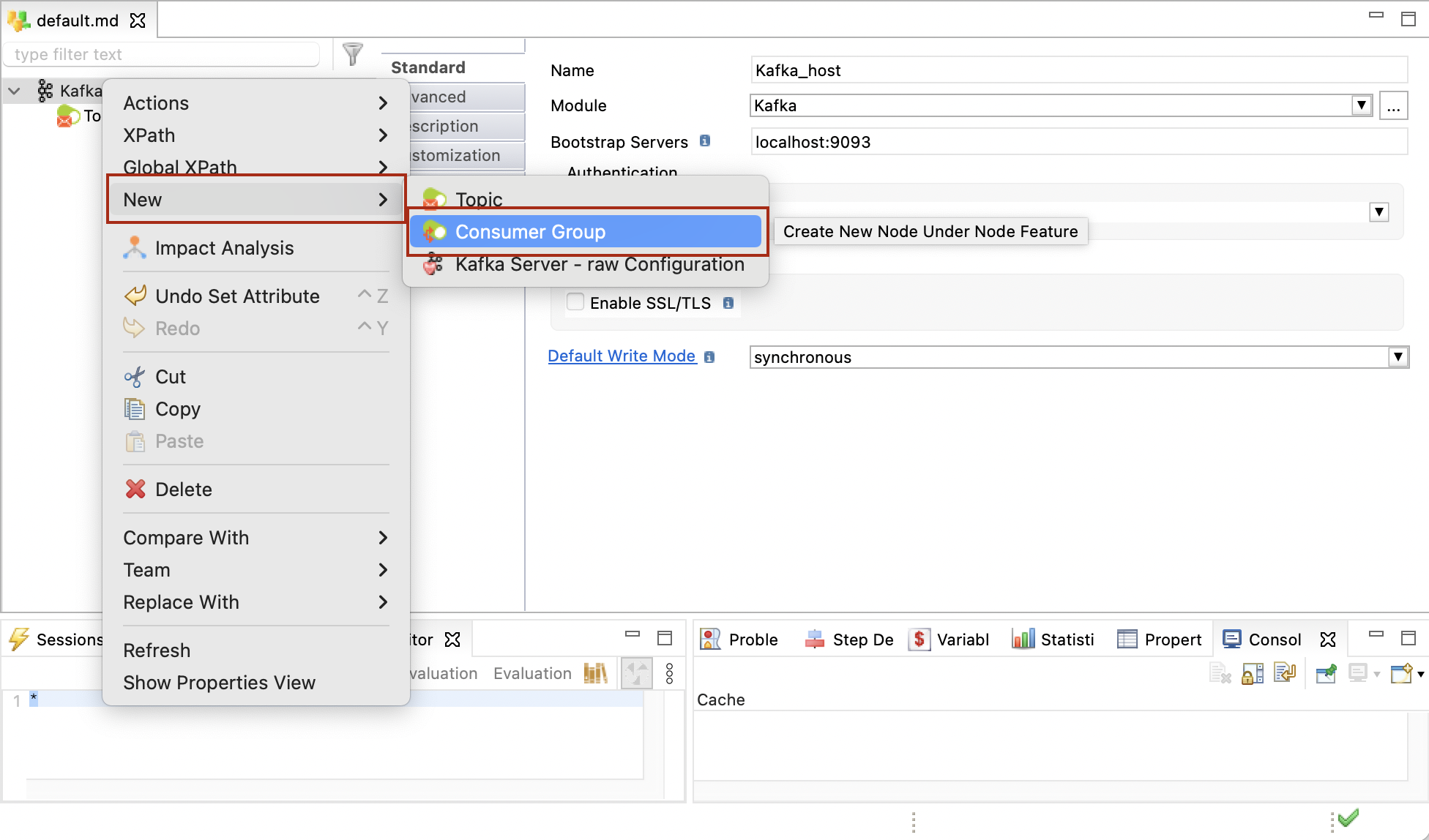
To define a consumer:
-
Right-click the host, then click New > Consumer Group.
-
Enter a name and a physical name for the consumer.
-
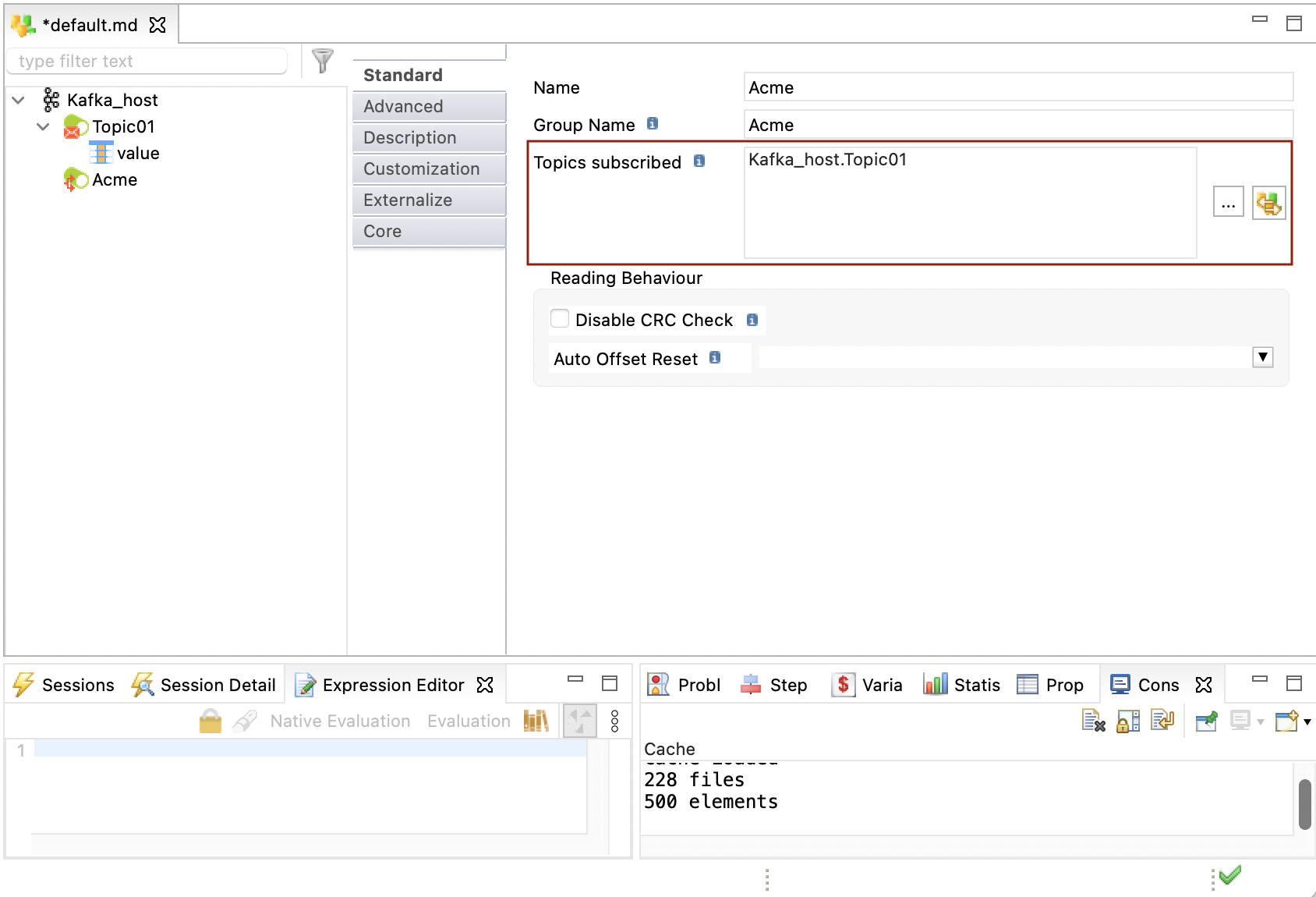
In the Topics subscribed field, add the topics to which the consumer should subscribe.
-
Optionally, define CRC Checks and Auto Offset Reset. These correspond to the [check.crcs] and [auto.offset.reset] Kafka properties.
-
Right-click the consumer, click New > Value, and set its type. The Value node corresponds to the Kafka message payload (Record) consumed from the topic.
You must define a single Value node for each consumer. 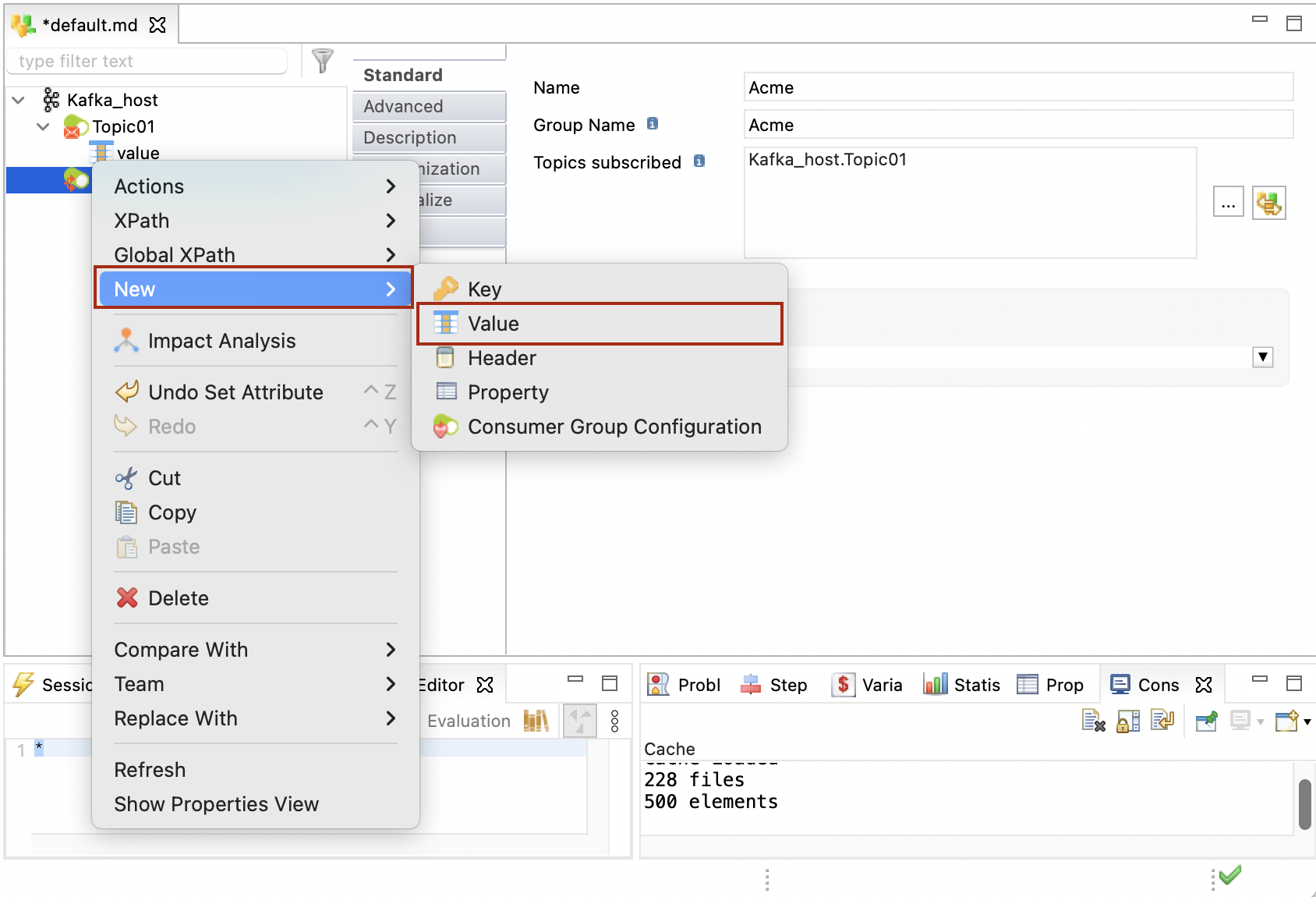
-
Add Key, Header, and Property nodes similarly to a topic definition. These fields are retrieved when consuming from the subscribed topics and can be used in mappings.
Create mappings
Mappings can be created for sending to (producer) and receiving (consumer) data from Kafka.
Producer mapping
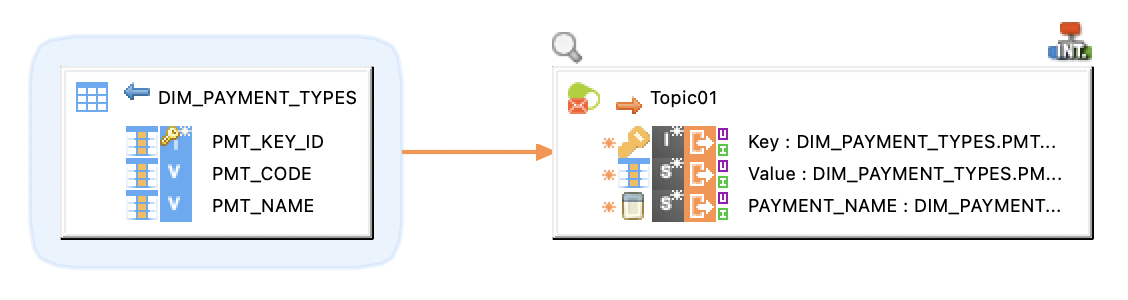
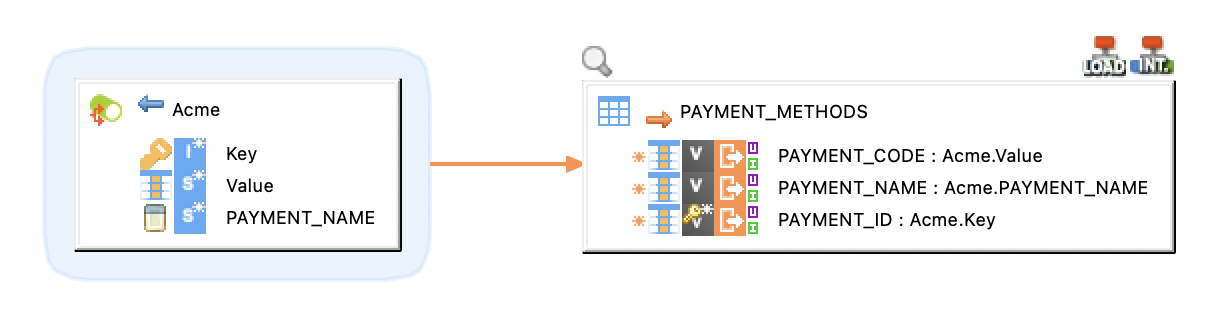
The following example illustrates a producer mapping in which a topic is used as a target. This mapping loads the Key and Value (message payload) from the database table and produces messages to the topic.
Sample project
The Apache Kafka component is distributed with sample projects that contain various examples and files. Use these projects to better understand how the component works, and to get a head start on implementing it in your projects.
Refer to Install components in Semarchy xDI Designer to learn about importing sample projects.
Development tips
When you create a consumer group, you can set the Auto Offset Reset to determine the read offset for the consumer group. However, this option only applies at the moment the group is created, which is when it is first used. It has no effect at other times.
If you want to reset a read offset for any consumer group, use the dedicated Kafka Reset Offsets process action in a process.