Using the Salesforce replicator in Incremental Mode
The Salesforce replicator can be used in Incremental mode, which captures all changes made in Salesforce objects since the last time a process was executed. This is a form of Change Data Capture (CDC).
These instructions explain how to use Incremental mode.
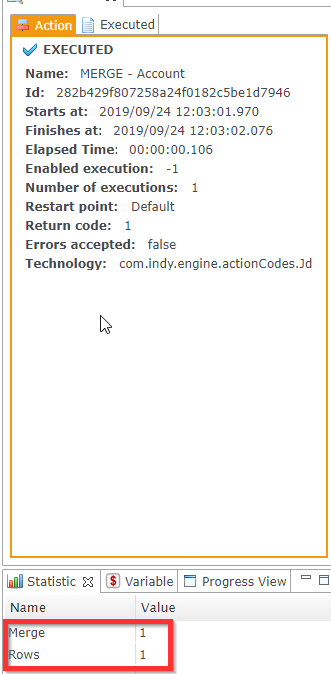
Initialize the tables
First, create the target table:
-
Create a new process.
-
Drag and drop the Salesforce replicator into the process. You can find it in the Process Palette, in Tools > Replicator Salesforce to Rdbms.
-
Drag and drop a source Salesforce server node onto the replicator. Make sure it is named SOURCE.
-
Drag and drop a target database table node onto the replicator. Make sure it is named TARGET.
-
Configure the replicator:
-
Uncheck the Unload Data option.
-
Check the Create Tables option.
-
Set the Table Prefix for the table you are creating. The prefix is set to
SF_by default.
-
-
Run this process to create the table.
You only need to create a table once. If you try to run the process again, Designer returns an error as the table already exists.
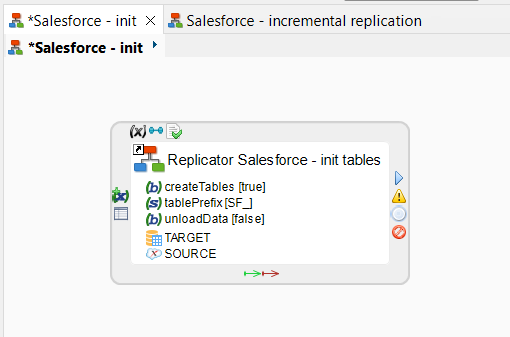
Incremental replication
Next, create a second process that will perform the actual replication:
-
Create a new process.
-
Drag and drop a new instance of the Salesforce replicator into the process.
-
Drag and drop the same source and target nodes onto the replicator as in the last step, with the same names.
-
Configure the replicator:
-
Set the Target Table Prefix to the one you chose in the first step.
-
Set the Table Prefix to a new value. This prefix is used by the replicator for its work tables.
-
Check the Create Tables and Drop Tables options. These options drop and recreate work tables at each execution.
-
Check the Load Data option so that the data from Salesforce is loaded to the target tables.
-
Set the Incremental Mode option to
mergeto activate incremental mode with CDC.
-
The replicator first finds the most recent update time in the target tables, and saves them as process parameters. These times are based on values in the LastModifiedDate column, a standard Salesforce column containing the last record modification date.
The replicator exports data from Salesforce, using the saved update time to select data newer than the last update to the target table.
Exported data is loaded into work tables, which are then used in MERGE expressions to move the new data into the target table.
Examples
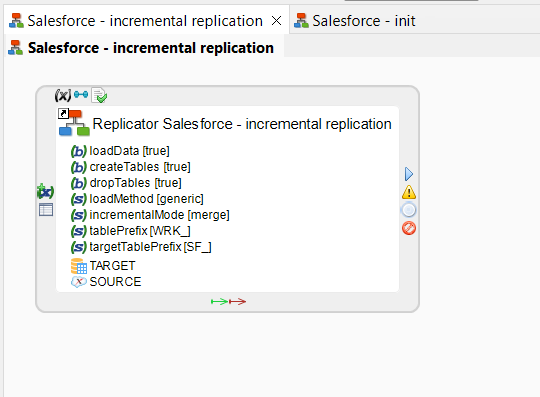
We start by running the initialization process to create the target table.
We then run the replication process with a Salesforce object that contains nine rows. As our target table starts out empty, this process replicates all nine rows from our source Salesforce object to the target table.
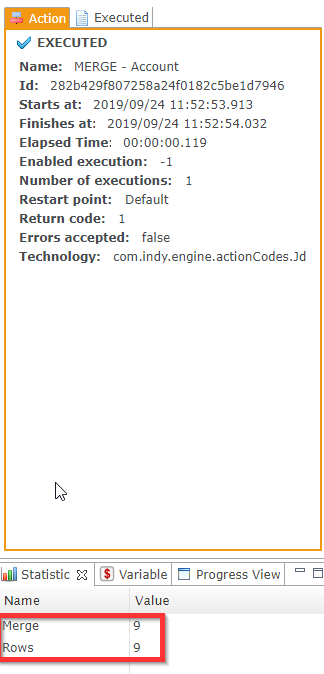
Next, we run the replication process again immediately. As no updates were made in Salesforce, nothing is replicated to the target table.
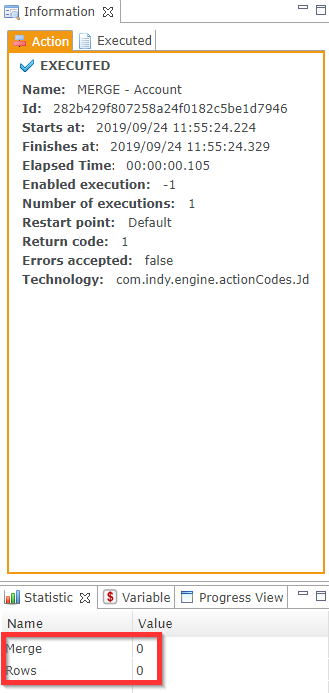
Finally, we make one update in Salesforce, and run the replication process a third time. Only this update is replicated to the target table.