Deserialize source data
This document describes how to use the deserializer in mappings.
The deserializer reads semi-structured data embedded within a source datastore field, and exposes it as a data structure that can be manipulated and loaded to a target datastore. It is useful in situations where you have JSON or XML data in a single database column, such as a LONGVARCHAR column, and you want to process it as its native data structure. The deserializer lets you manipulate this embedded JSON or XML data with the same ease as a physical JSON or XML file.
The deserializer templates offered in mappings are based on the computed output format. For example, when the output is in JSON format, you will see options for a JSON deserializer.
Refer to Templates for the list of currently supported formats and templates.
Create a deserializer
To create and configure a deserializer in a mapping:
-
Create the deserializer:
-
Drag and drop a database schema in the mapping.
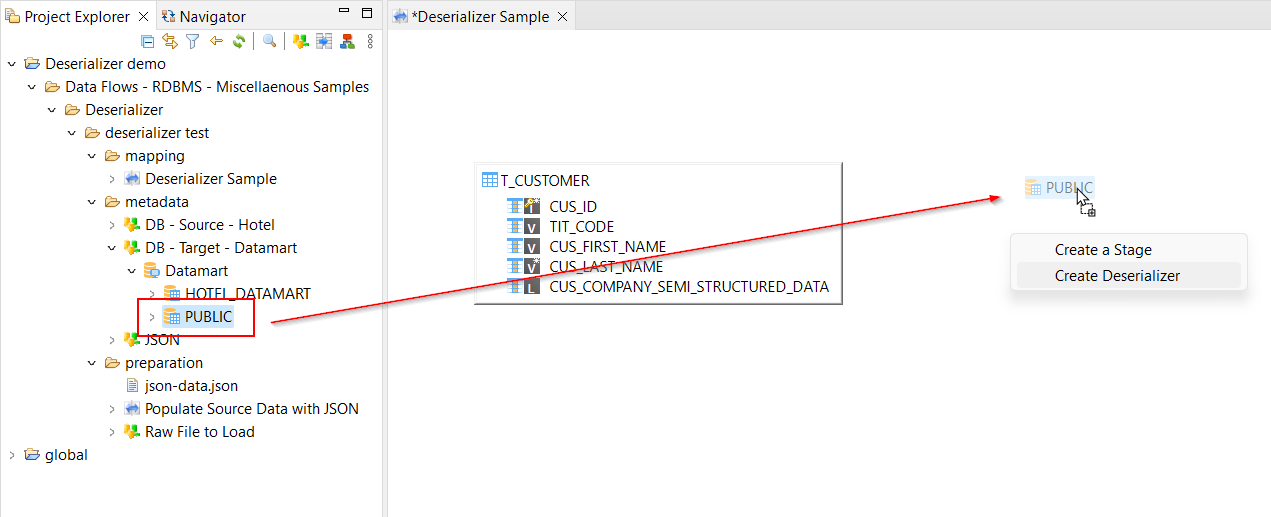
-
Or drag and drop a field from a datastore in the mapping and then select a database schema.
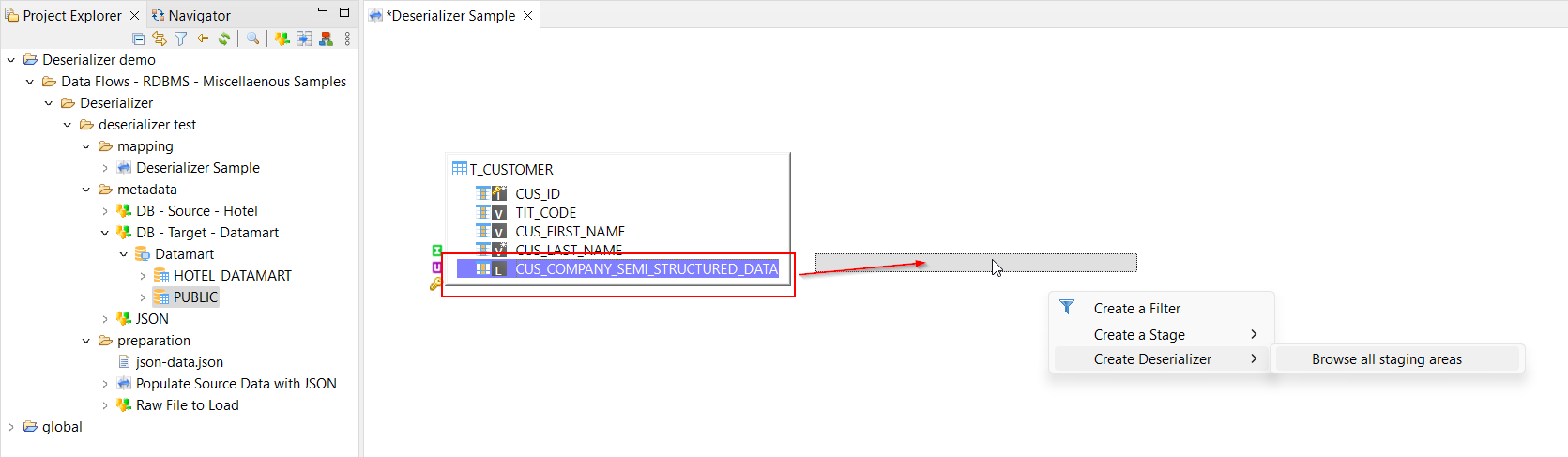
The database schema that is selected is used by the deserializer as a backend engine to process the semi-structured data with the runtime capabilities. Selecting the database schema used as the backend is mandatory.
-
-
Add fields (Optional).
Configure a deserializer
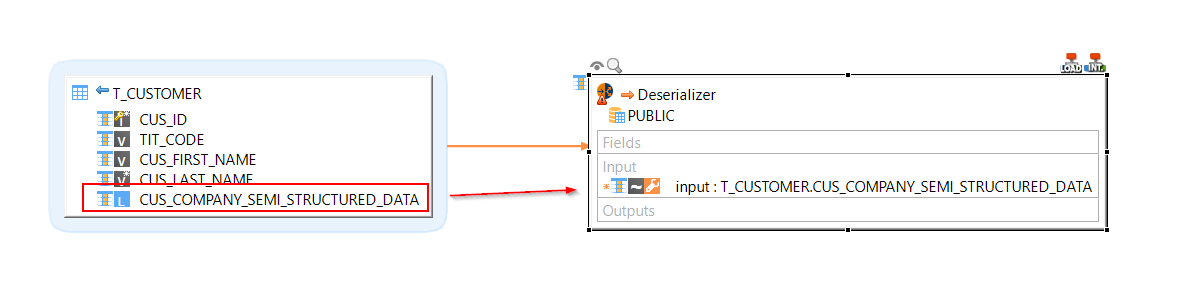
Add input
The input is the source datastore field containing the embedded semi-structured data.
To define the input of the deserializer, drag and drop the field that contains the embedded semi-structured data from the source datastore on Input.
Add output
The output is a reverse-engineered metadata representing the structure of the input data, such as, for example, a JSON metadata.
To define the output of the deserializer, drag and drop a previously reverse-engineered metadata representing the expected data structure on Output.
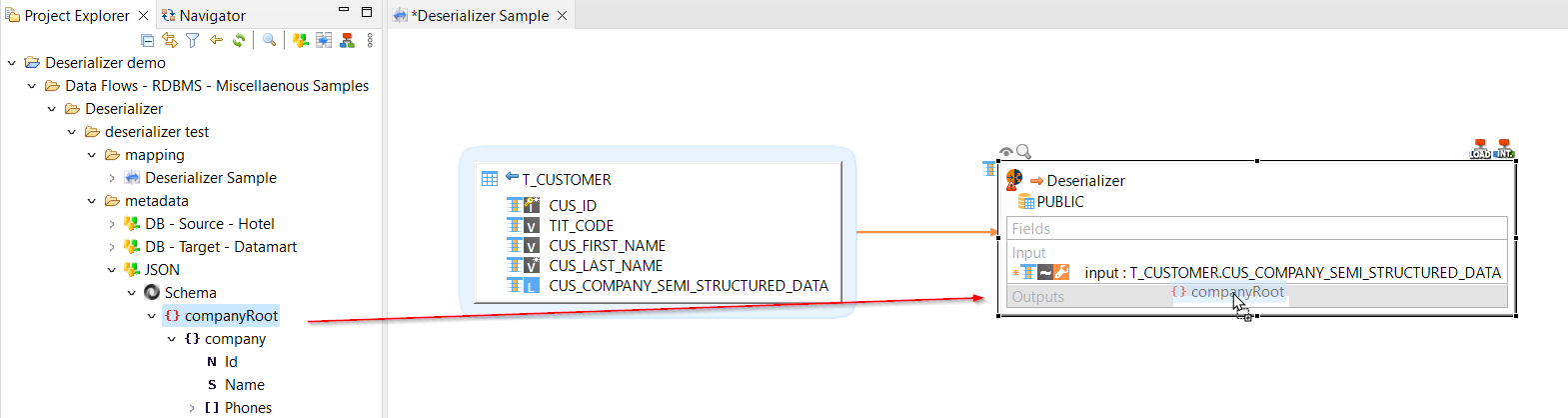
| The output structure must match the structure contained in the input data. |
Finally, use the output structure as a source to load your target datastore.
When the mapping is executed, the deserializer parses the semi-structured data from the input field and loads it into the output structure. Finally, the data from the output is loaded into the mapped fields in the target datastore.
| The deserializer templates proposed are computed from the output structure format. When the output is of JSON format, JSON deserializer templates are proposed. Refer to Templates for the full list of supported formats and templates. |
Add fields
Deserializer fields are optional containers to store source columns' data alongside the output structure data.
Create fields when you need to load and process data from other columns that the one containing the semi-structured data, or when you need to join two deserializers.
To add deserializer fields:
-
In the top left corner of the deserializer, click the create field icon.
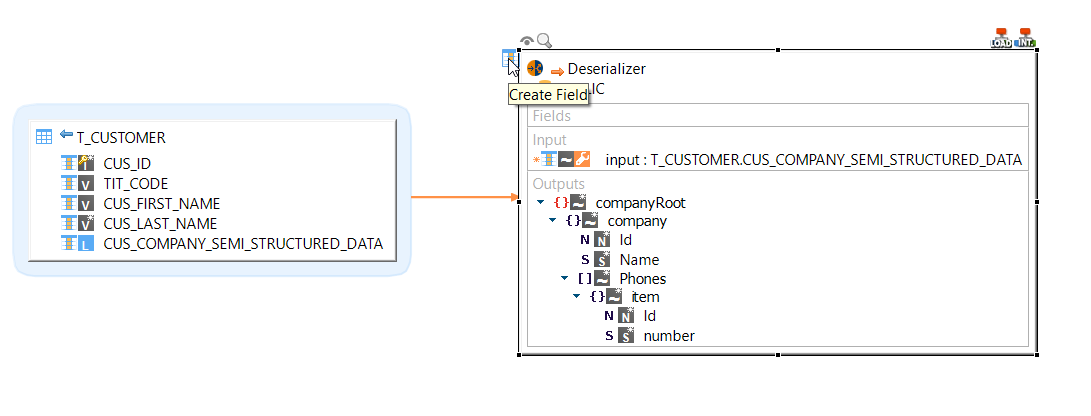
-
Drag and drop a field from the source datastore on the field that was created.
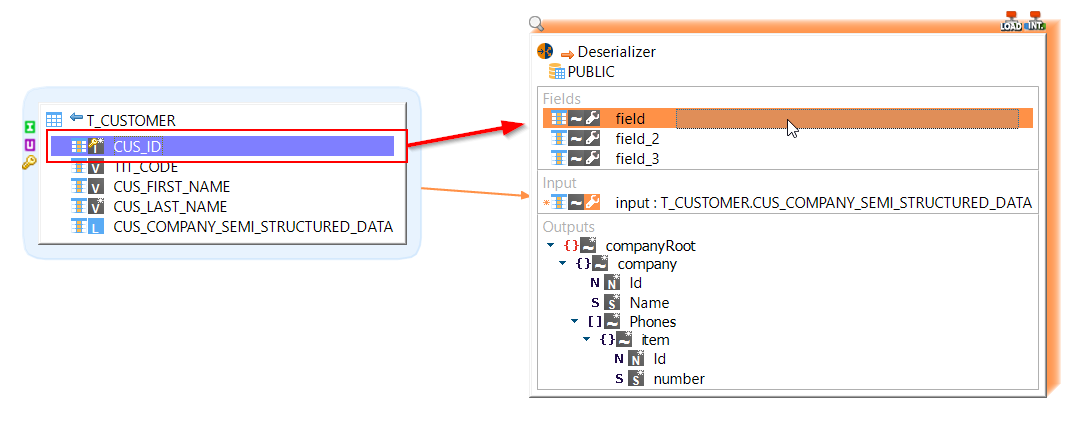
-
Repeat the procedure to add other fields.
Finally, use the fields as a source to map a target datastore or use them to join the deserializer with other datastores.
Join deserializers
You may have more than one deserializer in your mapping. In such a scenario, you can join them using fields.
To join two deserializers:
-
Select a deserializer and add the fields containing the data that will be used for the join. See Add fields.
-
Repeat the procedure for the other deserializer.
-
Drag and drop the field from one deserializer on the field in the other deserializer.
The two deserializers are joined. Use them as a source to load target datastores.
Sample mapping
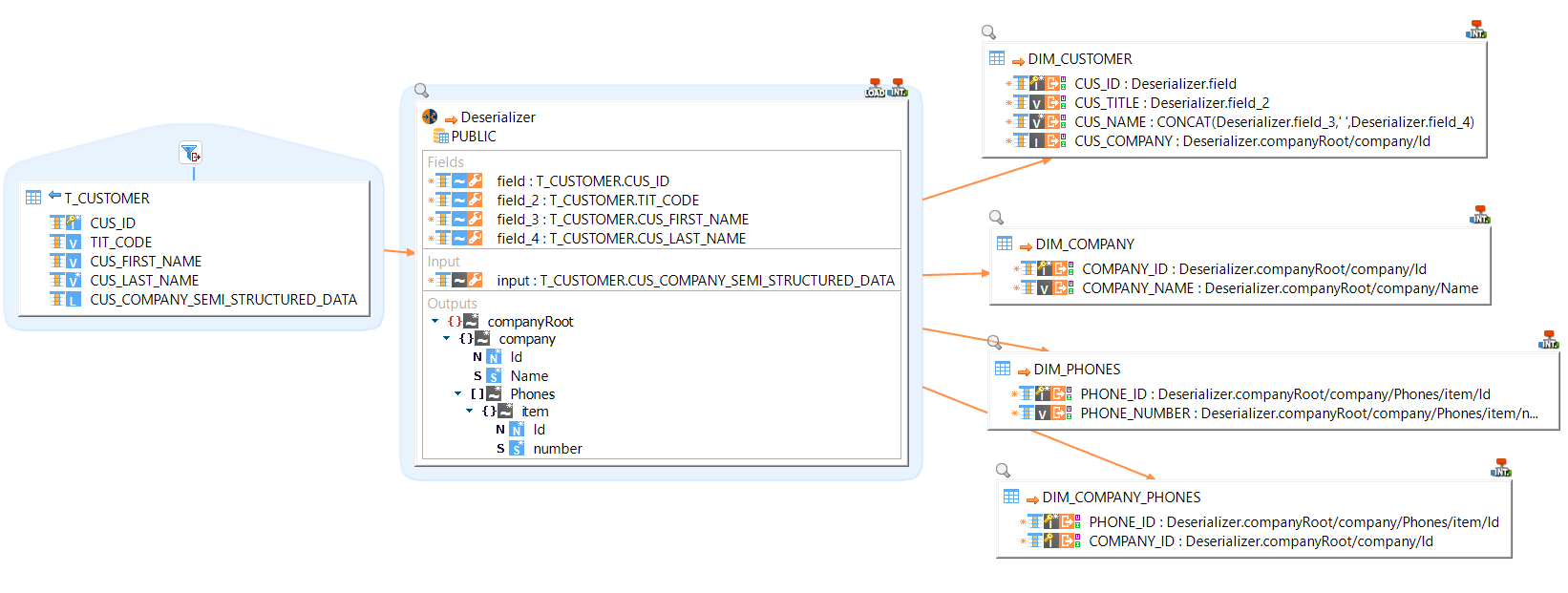
In this sample, the source table contains single columns data and a column with embedded semi-structure data.
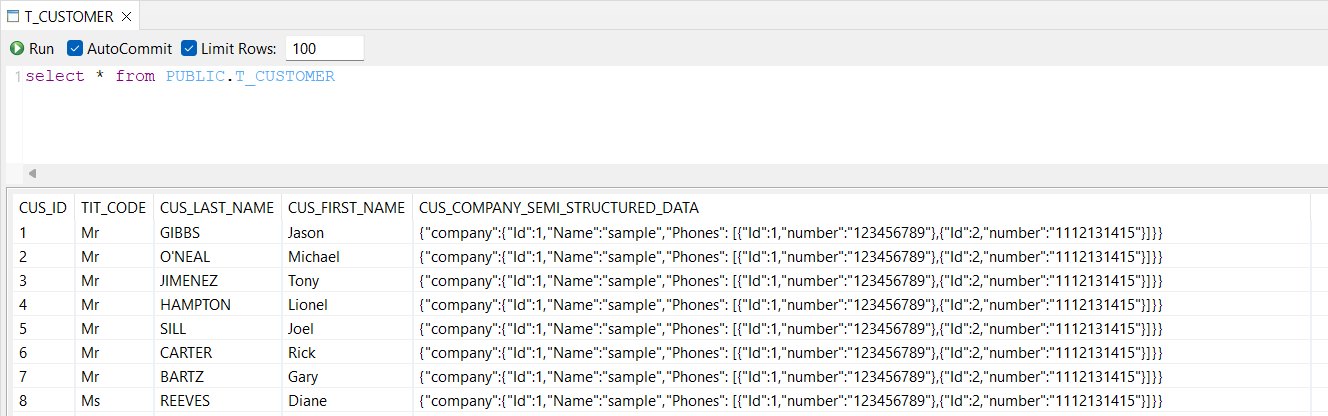
Through the deserializer, both are manipulated and loaded into multiple target datastores.
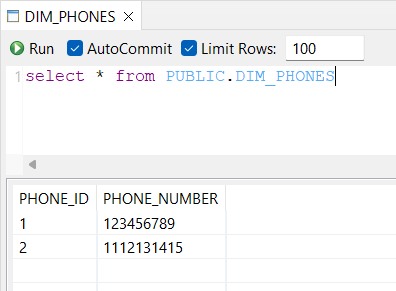
Below, an example of target datastore content, with the source semi-structured data extracted.
Templates
The deserializer provides two generic templates to deserialize data retrieved from a source RDBMS column:
-
DESERIALIZER RDBMS String as JSON, to parse JSON data.
-
DESERIALIZER RDBMS String as XML, to parse XML data.
It also provides technology-specific templates optimized for certain database providers.
Specific JSON deserializers
-
DESERIALIZER BigQuery String as JSON for a Google BigQuery source.
-
DESERIALIZER Greenplum String as JSON for a Greenplum source.
-
DESERIALIZER HSQL String as JSON for an HSQL source.
-
DESERIALIZER MySQL String as JSON for a MySQL source.
-
DESERIALIZER Oracle String as JSON for an Oracle source.
-
DESERIALIZER PostgreSQL String as JSON for a PostgreSQL source.
-
DESERIALIZER Redshift String as JSON for an Amazon Redshift source.
-
DESERIALIZER Snowflake String as JSON for a Snowflake string and VARIANT column source.