| This is documentation for Semarchy xDM 5.3 or earlier, which is no longer supported. For more information, see our Global Support and Maintenance Policy. |
The data certification process
Introduction to the certification process
The certification process creates consolidated and certified golden records from various sources:
-
Source records, pushed into the hub by middleware systems on behalf of upstream applications (known as the publishers).
Depending on the type of entity, these records are either converted to golden records directly (basic entities) or matched and consolidated into golden records (ID- and fuzzy-matched entities). When matched and consolidated, these records are referred to as master records. The golden records they have contributed to create are referred to as master-based golden records. -
Source authoring records, authored by users in the MDM applications.
When a user authors data in an MDM application, depending on the entity type and the application design, they perform one of the following operations:-
They creates new golden records or updates existing golden records that exist only for the hub, and do not exist in any of the publishers. These records are referred to as data-entry-based golden records. This pattern is allowed for all entities, but basic entities support only this pattern.
-
They create or update master records on behalf of publishers, submitting these records to matching and consolidation. This pattern is allowed only for ID- and fuzzy-matched entities.
-
They override golden-record values resulting from the consolidation of records pushed by publishers. This pattern is allowed only for ID- and fuzzy-matched entities.
-
-
Delete operations, made by users on golden and master records from entities with delete enabled.
-
Matching decisions, taken by data stewards for fuzzy-matched entities, using duplicate managers. Such decisions include confirming, merging or splitting groups of matching records as well as accepting/rejecting suggestions.
The certification process takes these various sources and applies the rules and constraints defined in the model in order to create, update, or delete the golden data that business users browse using the MDM applications and that downstream applications consume from the hub.
This process is automated and involves several phases, automatically generated from the rules and constraints, which are defined in the model based on the functional knowledge of the entities and the publishers involved.
The following sections describe the details of the certification process for ID, fuzzy matched and basic entities, and the delete process for all entities.
Rules involved in the process
The rules involved in the process include:
-
Enrichers: sequences of transformations performed on source and/or consolidated data to make it complete and standardized.
-
Data quality constraints: checks carried out on source and/or consolidated data to isolate or flag erroneous rows. These include referential integrity, unique keys, mandatory attributes, lists of values, SemQL and plugin validations.
-
Matchers: (for fuzzy-matched entities only) a set of match rules that bin (i.e., group), then match similar records to detect them as duplicates. The resulting duplicate clusters are merged (i.e., consolidated) and confirmed depending on their confidence score.
-
Survivorship rules: (for fuzzy-matched and ID-matched entities only) define how golden record values are computed. These rules include:
-
A consolidation rule: defines how to consolidate values from duplicate records (detected by the matcher) into a single (golden) record.
-
An override rule: defines how values authored by users override the consolidated value in the golden record.
-
Certification process for ID- and fuzzy-matched entities
The following figure describes the certification process and the various table structures involved in this process.
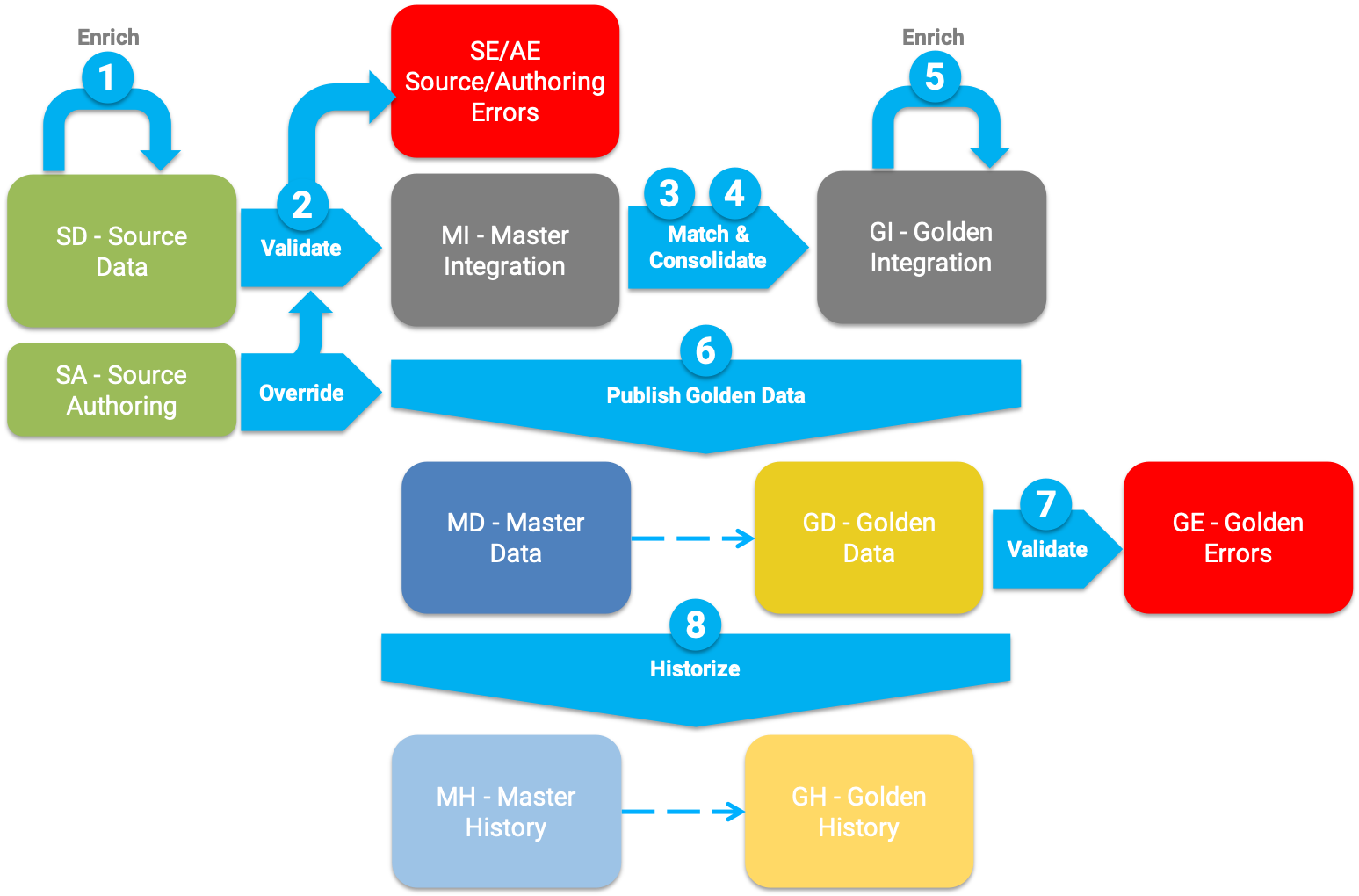
The certification process involves the following steps:
-
Enrich and standardize source data: source authoring records created or updated on behalf of publishers and source records are enriched and standardized using the SemQL and API (Java plugin or REST client) enrichers, executed pre-consolidation.
-
Validate source data: The enriched and standardized records are checked against the various constraints executed pre-consolidation. Erroneous records are ignored for the rest of the processing and the errors are logged.
Source authoring records are enriched and validated only for basic entities. For ID- and fuzzy-matched entities, source authoring records are not enriched and validated. -
Match and find duplicates: for fuzzy-matched entities, this step matches pairs of records using a matcher, and creates groups of matching records (i.e., match groups). For ID-matched entities, matching is made on the ID value.
The matcher works as follows:-
It runs a set of match rules. Each rule has two phases: first, a binning phase creates small bins of records. Then a matching phase compares each pair of records within these small bins to detects duplicates.
-
Each match rule has a match score that expresses how strongly the pair of records matches. A pair of records that match according to one or more rules is given the highest match score of all these rules.
-
When a match group is created, an overall confidence score is computed for that group. According to this score, the group is marked as a suggestion or immediately merged, and possibly confirmed. These automated actions are configured in the merge policy and auto-confirm policy of the matcher.
-
Matching decisions taken by users on match groups are applied at that point, superseding the matcher’s choices.
-
-
Consolidate data: this step consolidates match group duplicates into single consolidated records. The consolidation rules created in the survivorship rules defines how the attributes consolidate.
-
Enrich consolidated data: the SemQL and API (Java plugin or REST client) enrichers executed post-consolidation run to standardize or add data to the consolidated records.
-
Publish certified golden data: this step finally publishes the golden records for consumption.
-
This step applies possible overrides from source authoring record, according to the override rules defined as part of the survivorship rules.
-
This step also creates or updates data-entry-based golden records (that exist only in the MDM), from source authoring records.
-
-
Validate golden data: the quality of the golden records is checked against the various constraints executed on golden records (post-consolidation).
Unlike the pre-consolidation validation, it does not remove erroneous golden records from the flow but flags them as erroneous. The errors are also logged.
-
Historize data: changes made to golden and master data are added to their history if historization is enabled.
| Source authoring records are not enriched or validated for ID- and fuzzy-matched entities as part of the certification process. These records should be enriched and validated as part of the steppers into which users author the data. |
Certification process for basic entities
The following figure describes the certification process and the various table structures involved in this process.
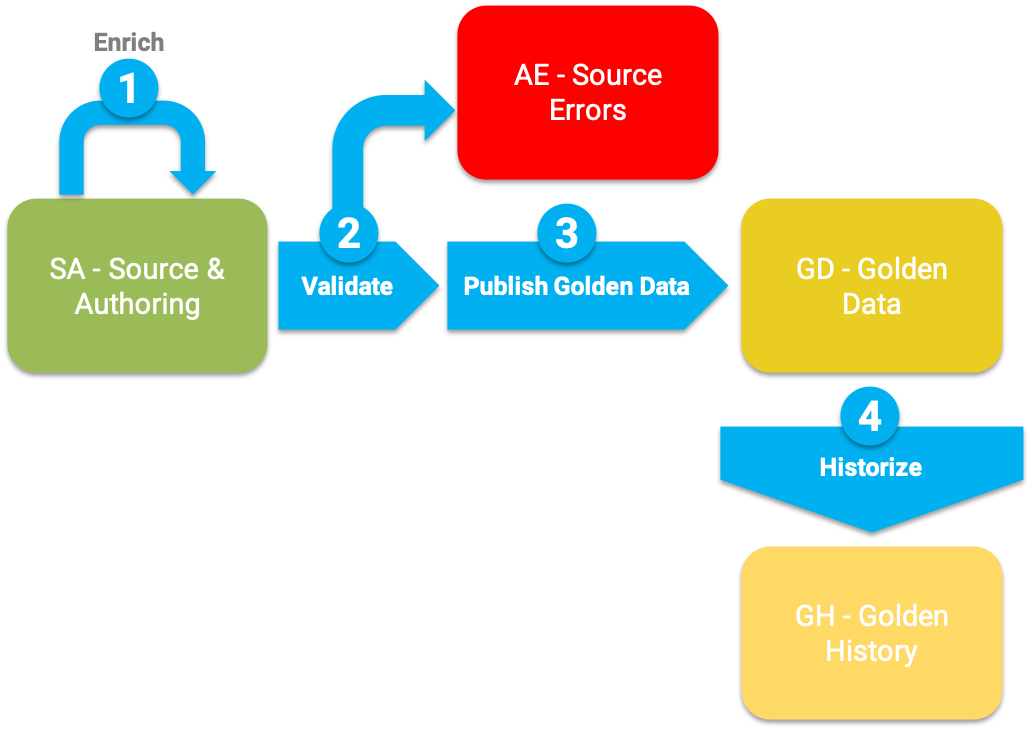
The certification process involves the following steps:
-
Enrich and standardize source data: during this step, the source records and source authoring records are enriched and standardized using SemQL and API (Java plugin and REST client) enrichers executed pre-consolidation.
-
Validate source data: the quality of the enriched source data is checked against the various constraints executed pre-consolidation. Erroneous records are ignored for the rest of the processing and the errors are logged.
-
Publish certified golden data: this step finally publishes the golden records for consumption.
-
Historize data: changes made to golden data changes are added to their history if historization is enabled.
|
Deletion process
Performing a delete operation (for basic, ID-matched, or fuzzy-matched entities) on a golden record involves the following steps:
-
Propagate through cascade: extends the deletion to the child records directly or indirectly related to the deleted ones with a cascade configuration for delete propagation.
-
Propagate through nullify: nullifies child records related to the deleted ones with a nullify configuration for the delete propagation.
-
Compute restrictions: removes from deletion the records having related child records and a Restrict configuration for the delete propagation. If restrictions are found, the entire delete is canceled as a whole.
-
Propagate delete to owned master records to propagate deletion to master records attached to deleted golden records. This step only applies to ID- and fuzzy-matched entities.
-
Publish deletion: tracks records with the record values for soft deletes only, and then removes the records from the golden and master data. When doing a hard delete, this step deletes any trace of the records in every table. The only trace of a hard delete is the ID (without data) of the deleted master and golden records. Deletes are tracked in the history for golden and master records, if historization is configured.
| It is not necessary to configure in the job all the entities deletion should cascade to. The job generation automatically detects the entities that must be included for deletion based on the entities managed by the job. |