| This is documentation for Semarchy xDI 5.3 or earlier, which is no longer supported. For more information, see our Global Support and Maintenance Policy. |
Loading Data into Amazon Redshift through S3 Buckets
When you need to load data from your local databases to Amazon Redshift, Semarchy xDI lets you design a simple mapping which will take care of the following steps automatically:
-
Export data from your database to a file
-
Send the file to an Amazon S3 bucket
-
Load the S3 file into Redshift
This article shows how to create the required metadata and how to design the mapping.
Create The Amazon S3 Metadata
Create an Amazon S3 Metadata:
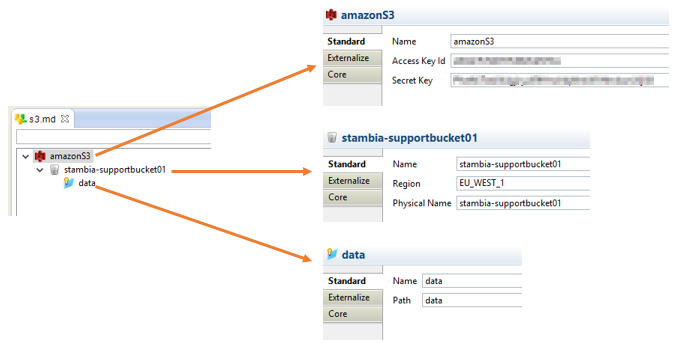
Right click to add a bucket and a folder. You can configure each node:
Create The Amazon Redshift Metadata
Create an Amazon Redshift Metadata:
Fill in the JDBC URL and credentials, and reverse your Redshift database schema as you would do with any database.
Once this is done, drag and drop the S3 Folder into the Redshift schema, like this:
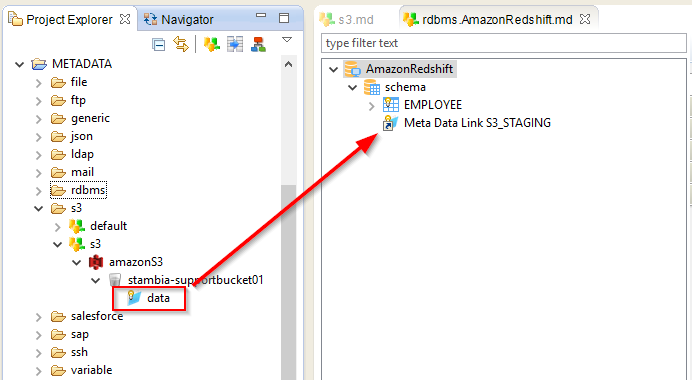
Rename this node as "S3_STAGING". The Load templates will need this name to connect to this folder.