| This is documentation for Semarchy xDI 5.3 or earlier, which is no longer supported. For more information, see our Global Support and Maintenance Policy. |
Getting Started with Hadoop Distributed File System (HDFS)
Overview
This getting started gives some clues to start working with Hadoop Distributed File System (HDFS)
Connect to your Data
The first step, when you want to work with HDFS in Semarchy xDI, consists of creating and configuring the HDFS Metadata.
Here is a summary of the main steps to follow:
-
Create the HDFS Metadata
-
Configure the Metadata
-
Configure Kerberos security (optional)
-
Define HDFS folders
Below, a quick overview of those steps:
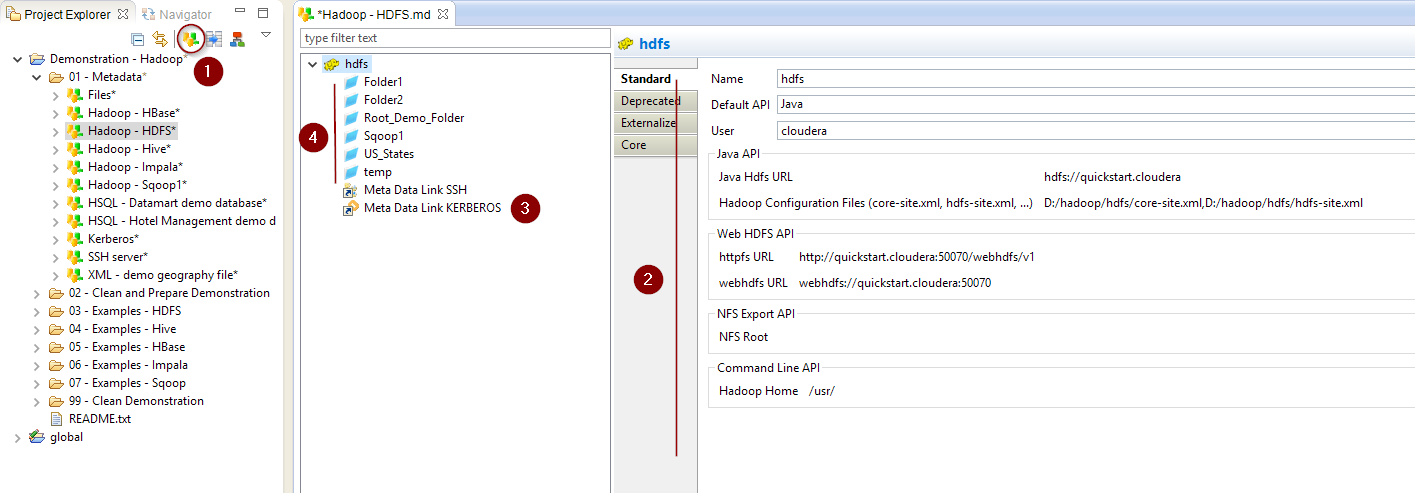
Create the Metadata
Create first the HDFS Metadata, as usual, by selecting the Hadoop Distributed File System technology in the Metadata Creation Wizard.
Choose a name for this Metadata and go to next step.
Configure the Metadata
The Component offers the possibility to use several HDFS APIs to perform the operations, leaving the choice of the preferred method to the user.
This will impact on the way Semarchy xDI will connect and perform operations on HDFS.
Depending on the API you are planning to use, you’ll have to define the corresponding properties.
The following APIs are available:
API |
Description |
Kerberos support |
Java |
The Java APIs are used to perform the operations. + This requires to have HDFS third-party libraries available in Hadoop Module. |
Yes |
Web HDFS |
The Web HDFS APIs consists of using RESTful web APIs to perform the operations. + Semarchy xDI will call the REST APIs corresponding to the operations. |
Not currently supported |
NFS Export |
Semarchy xDI performs the operations directly through a NFS Gateway. +
The NFS Gateway must be installed on the system where the Runtime is located. + Please refer to the Apache documentation for further information about how to install a NFS Gateway for HDFS on the file system. |
Yes |
Command Line [Over SSH] |
The Hadoop command lines are used to perform the operations. + Semarchy xDI will execute the commands corresponding to the operations, in the local system or in a remote server through SSH, depending on the chosen option. |
Not currently supported |
In the HDFS Metadata, click on the root node and choose the default API to use for this Metadata.
Then, define the corresponding properties.
Below is an example for the various APIs.
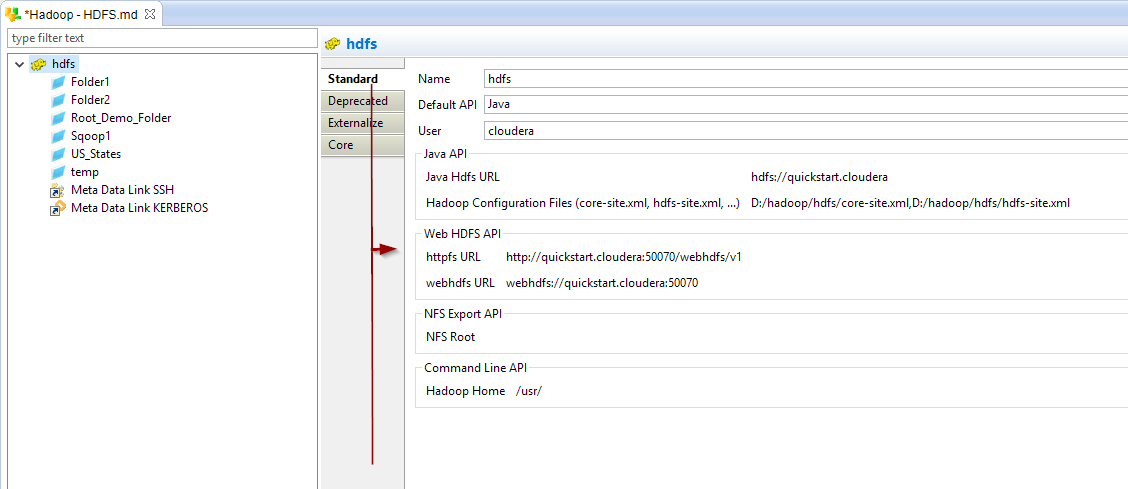
The following properties are available:
Property |
Description |
API |
Examples |
Name |
Label of the Hadoop server |
||
Default API |
Default HDFS API used to operate on the server:
|
||
Java Hdfs URL |
Base URL used by the Java API to perform the operations. |
Java |
hdfs://sandbox.hortonworks.com +
hdfs://quickstart.cloudera + maprfs:///mapr.sandboc |
Hadoop Configuration Files |
Hadoop stores information about the services properties in configurations file such as core-site.xml and hdfs-site.xml. +
These files are XML files containing a list of properties and information about the Hadoop server. +
Depending on the environment, network, and distributions, these files might be required for the Java API to be able to contact and operate on HDFS. +
There is therefore the possibility to specify these files in the Metadata to avoid network and connection issues, for instance. + For this simply specifies them with a comma separated list of paths pointing to their location. They must be reachable by the Runtime. |
Java |
D:/hadoop/hdfs/core-site.xml,D:/hadoop/hdfs/hdfs-site.xml |
Httpfs URL |
HTTP URL used by the WebHDFS API |
Web HDFS |
|
Webhdfs URL |
WEBHDFS FileSystem URI used by WebHDFS API |
Web HDFS |
webhdfs://<hostname>:<port> + webhdfs://quickstart.cloudera:50070 |
Hadoop Home |
Root directory where the HDFS command line tools can be found.
This should be the directory just before the "bin" folder. + This is used by Semarchy xDI, for the Command Line API, to calculate the path of the HDFS command lines. |
Command Line |
/usr/ |
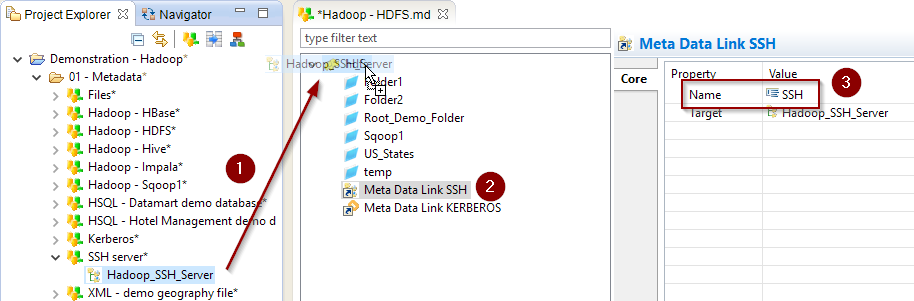
If you are using the Command Line Over SSH API, you must drag and drop an SSH Metadata Link containing the SSH connection information in the HDFS Metadata.
Then, rename it to 'SSH'.
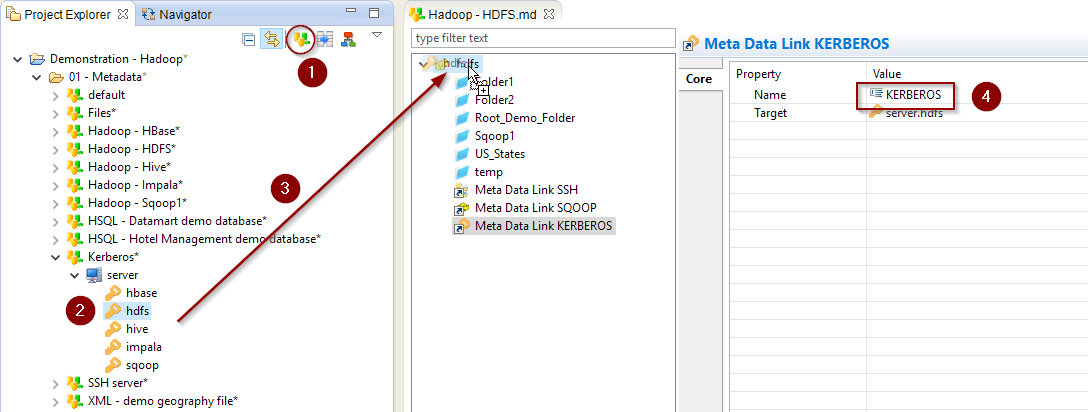
Configure the Kerberos Security (optional)
When working with Kerberos secured Hadoop clusters, connections will be protected, and you’ll therefore need to specify in Semarchy xDI the credentials and necessary information to perform the Kerberos connection.
Java, Command Line, and Command Line Over SSH APIs
A Kerberos Metadata is available to specify everything required.
-
Create a new Kerberos Metadata (or use an existing one)
-
Define inside the Kerberos Principal to use for HDFS
-
Drag and drop it in the HDFS Metadata
-
Rename the Metadata Link to 'KERBEROS'
Below, an example of those steps:
|
| Refer to Getting Started With Kerberos for more information. |
Perform HDFS Operations
Overview
Once the Metadata is configured, you can now start making operations on HDFS.
You have for this at your disposal a list of TOOLS dedicated to each operation, which you can find in the Process Palette.
The following tools are available:
Name |
Description |
TOOL HDFS File Mkdir |
Create an HDFS directory |
TOOL HDFS File Put |
Send a file to HDFS |
TOOL HDFS File Mv |
Move a file or folder |
TOOL HDFS File Get |
Retrieve a file from HDFS locally |
TOOL HDFS File Set Properties |
Set properties on a file or directory, such as permissions, owner, group, or replication |
TOOL HDFS File Delete |
Delete a file or folder from HDFS |
Sample Project
The Hadoop Component ships sample project(s) that contain various examples and use cases.
You can have a look at these projects to find samples and examples describing how to use it.
Refer to Install Components to learn how to import sample projects.