| This is documentation for Semarchy xDI 5.3 or earlier, which is no longer supported. For more information, see our Global Support and Maintenance Policy. |
Getting Started with Snowflake
This getting started gives some clues to start working with Snowflake
Connect to your Data
The database structure can be entirely reversed in metadata and then used in mappings and processes to design and adapt the business rules to meet the user’s requirements.
You can refer to Connect to your Data page which explains the procedure.
Below is an example of reversed Snowflake metadata.
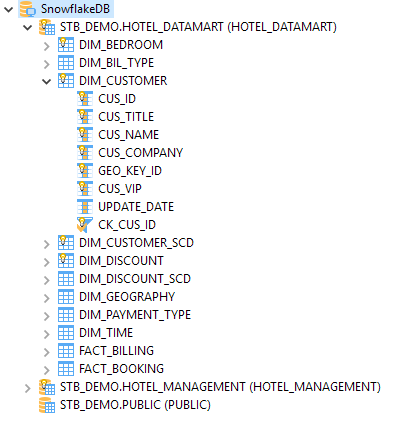
Temporary Storage
Overview
To optimize data loading into Snowflake, Semarchy xDI uses a temporary storage location to store temporary files before loading them into Snowflake.
When necessary, source data is first extracted to temporary files which are sent into this temporary storage location, before being loaded into Snowflake using the dedicated Snowflake loaders.
Currently, Semarchy xDI supports the following storage locations:
-
Internal Snowflake Stage
-
External Storage
-
Microsoft Azure Storage
-
Amazon S3
-
Storage definition
The storage information is defined in the Snowflake metadata.
On the Snowflake metadata server node:
-
Select the Storage tab.
-
Define the Storage Method property.
-
Define the External Storage property if you are using external storage.
-
(Optional) Change the Compression Behavior.
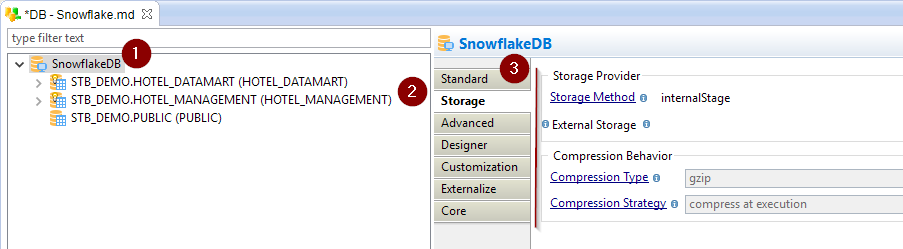
The following properties are available:
| Property | Description | ||
|---|---|---|---|
Storage Method |
Storage method used as default in mappings loading data into Snowflake.
|
||
External Storage |
Metadata link of the external storage container to be used when using external storage method. Choose in the list the external storage, or drag and drop it inside the property.
|
||
Compression Type |
Defines the compression type used when loading files (source files or temporarily generated files) into this database. |
||
Compression Strategy |
Defines the compression behavior when loading files (source files or temporarily generated files) into this database.
|
|
Those attributes can be overridden per schema and per table: for this, go on the desired schema or table node, then go inside the 'Storage' tab where you’ll find the same attributes, which will override the value set on the parent nodes. |
| 'External Storage' is not linked to the 'Storage Method'. You can decide to use 'internalStage' storage method but provide an External Storage link for specific cases where you’ll override the default storage method. |
Definition of an external storage
As indicated in the above properties documentation, you can define the external storage location by selecting the related location, or by dragging and dropping it directly on the property.
To define an external storage, the prerequisite is to have the corresponding metadata existing in your workspace.
Example through a drag and drop:

| Refer to Getting Started with Microsoft Azure Blob Storage and Amazon S3 to learn how to create this metadata. |
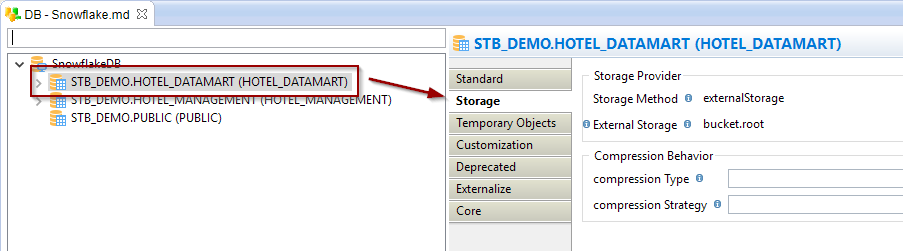
Override of storage configuration
The storage configuration that is defined on the server node can be overridden on schema, on table, and directly in mappings.
This offers the ability to have a common default behavior and override it when it is required for some specific developments or use cases.
Example of an override on a schema node:
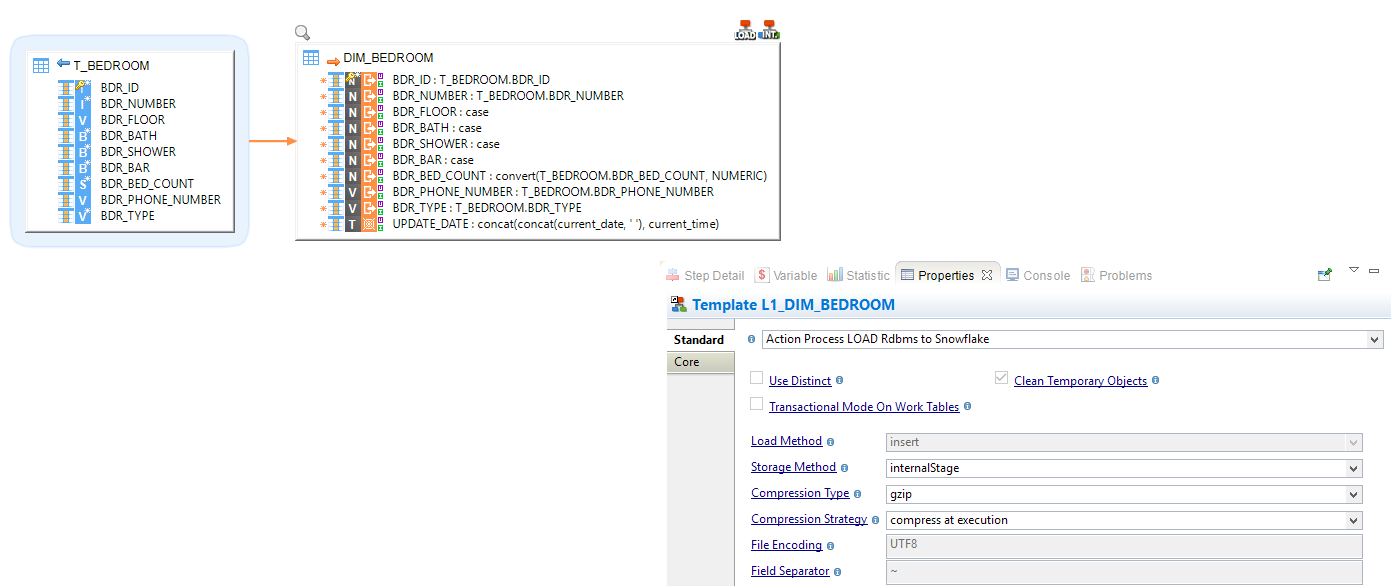
Example of an override in a mapping:
VARIANT Data Type
The VARIANT data type allows storing structured data such as JSON, AVRO, or XML.
Semarchy xDI supports reading data inside columns with this data type.
Reverse engineering of the data structure is also supported through the following procedure:
-
In the Snowflake metadata, select the column with the VARIANT data type.
-
Fill the Data Structure property with the JSON schema corresponding to the structure of data contained in the column.
Use the […] button that is close to the Data Structure property to open a wizard that helps fill this property. The wizard has different options to generate the JSON schema from a sample of data, files, and more… -
Right-click the column, select Actions, then Reverse Datastructure.
|
Create your first mappings
Your metadata is ready and your tables reverse engineered, you can now create your first mappings.
The Snowflake technology can be used like any other database in Semarchy xDI.
Drag and drop your sources and targets, map the columns as usual, and configure the templates accordingly to your requirements.
Loading data from a database into Snowflake
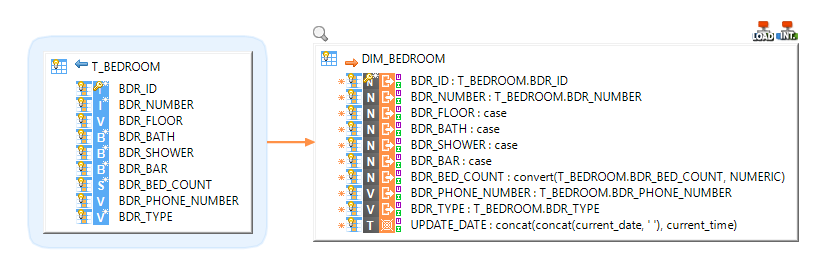
Loading data from a Delimited File into Snowflake
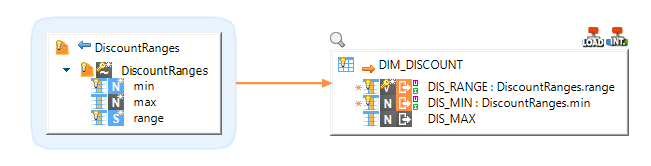
Loading data from Snowflake into another database
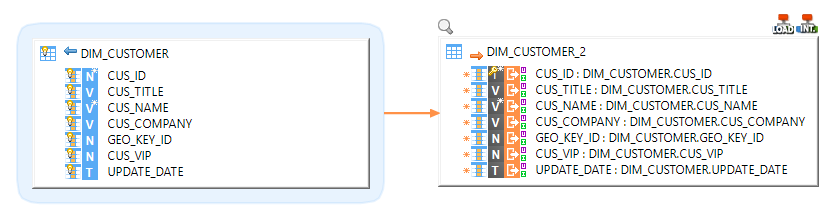
Performing Reject detection while loading a Snowflake Table
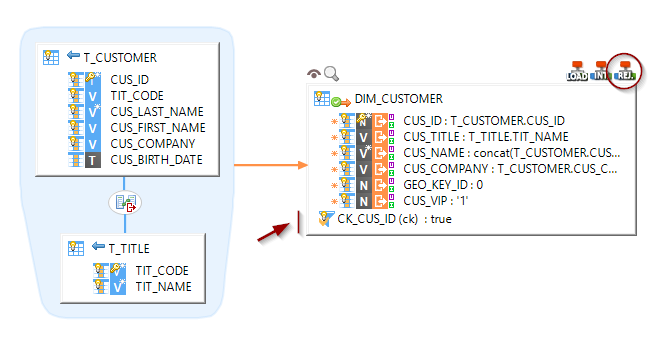
Loading structured data contained in a VARIANT field into another database
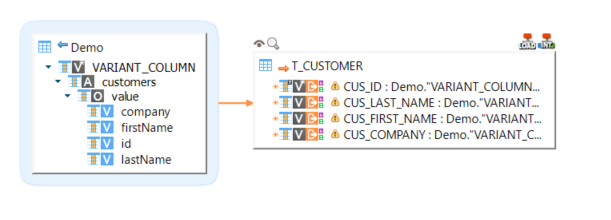
| The warnings on the target fields are displayed because of the hierarchical structure that is currently unknown by the expression parser. They can be ignored. |
Replicating a source database into Snowflake

Sample Project
The Snowflake Component ships sample project(s) that contain various examples and use cases.
You can have a look at these projects to find samples and examples describing how to use it.
Refer to Install Components to learn how to import sample projects.