| This is documentation for Semarchy xDI 5.3 or earlier, which is no longer supported. For more information, see our Global Support and Maintenance Policy. |
Getting Started with Google BigQuery
Prerequisites
Google Cloud Project Metadata
You must create a Google Cloud Project Metadata, which contains the account and credentials to connect to Google BigQuery.
This is mandatory, Google BigQuery Metadata will use it to gather the account and credentials.
Google Cloud Storage Metadata
Google Cloud Storage is used as a temporary location for temporary files to optimize data loading on Google BigQuery.
It is recommended to create a Google Cloud Storage Metadata, to define this temporary location.
Connect to your Data
Create the Metadata
To create a Google BigQuery Metadata, launch the Metadata creation wizard, select the Google BigQuery Metadata in the list and follow the wizard.
The wizard will ask you to choose the credentials to use, with a list of all credentials defined in your workspace. If the list is empty, make sure that you have read carefully the prerequisites.
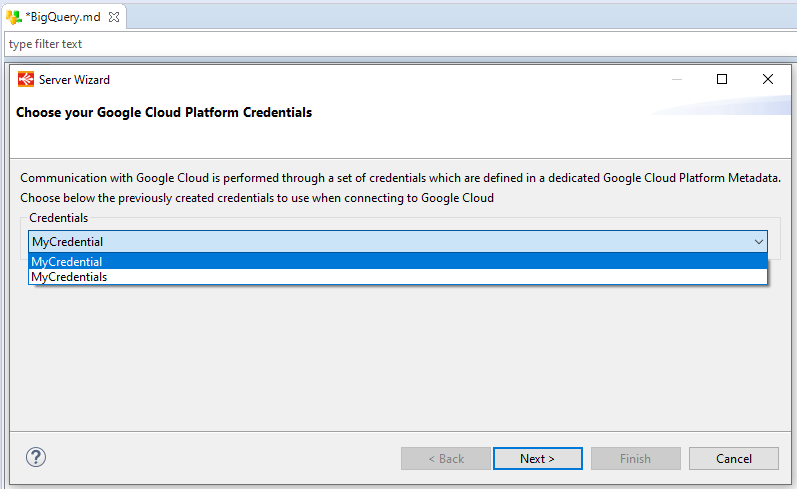
Select the credentials, click next, optionally customize the URL and click Connect.
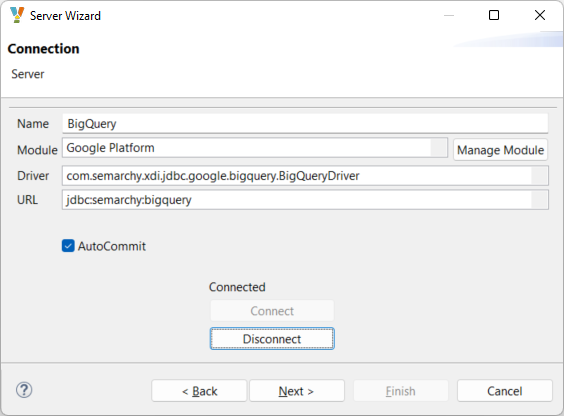
The JDBC URL supports the following optional parameters:
| Parameter | Description |
|---|---|
backendErrorRetryNumber |
The number of job retries to perform when a jobBackendError or jobInternalError happens. When reaching the defined number, if the error persists, the job will stop and throw the error. When the parameter is undefined, the job stops immediately when one of these errors is encountered and the corresponding message is displayed. |
backendErrorRetryDelay |
Delay in milliseconds to wait between each retry. |
|
The parameters are defined in the JDBC URL using the standard syntax. E.g. jdbc:semarchy:bigquery?backendErrorRetryNumber=2&backendErrorRetryDelay=1000 |
On the next page, click Refresh Values on the Catalog Name, then select the Google Project from the list.
Click Refresh Values onto the Schema Name and select the Google BigQuery dataset to reverse-engineer from the list.
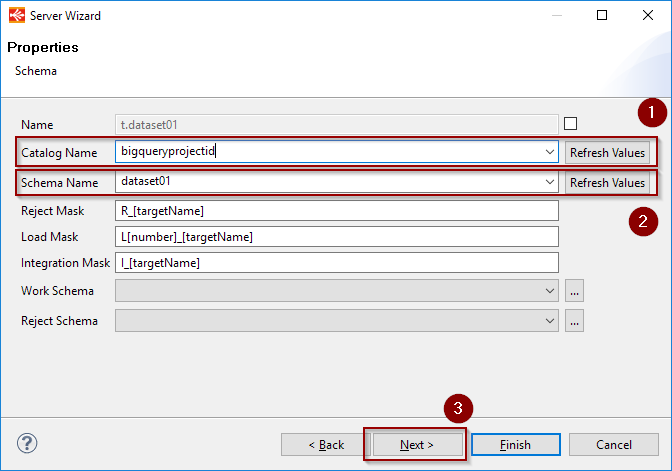
Click next, click Refresh to list the tables and select the ones to reverse-engineer.
Finally, click the Finish button. The tables will be reverse-engineered in the Metadata.
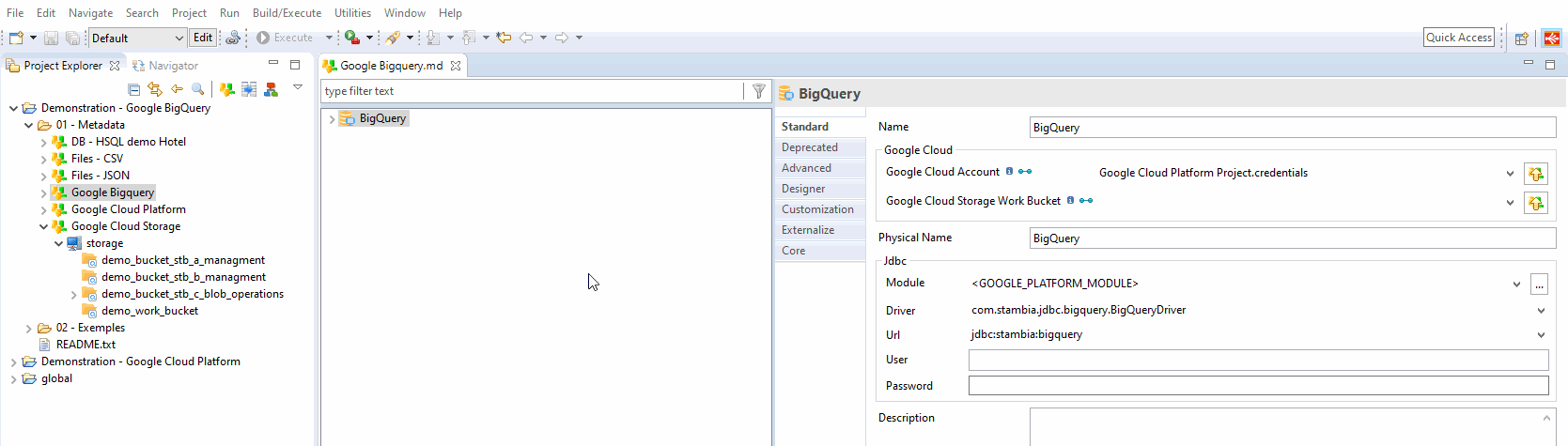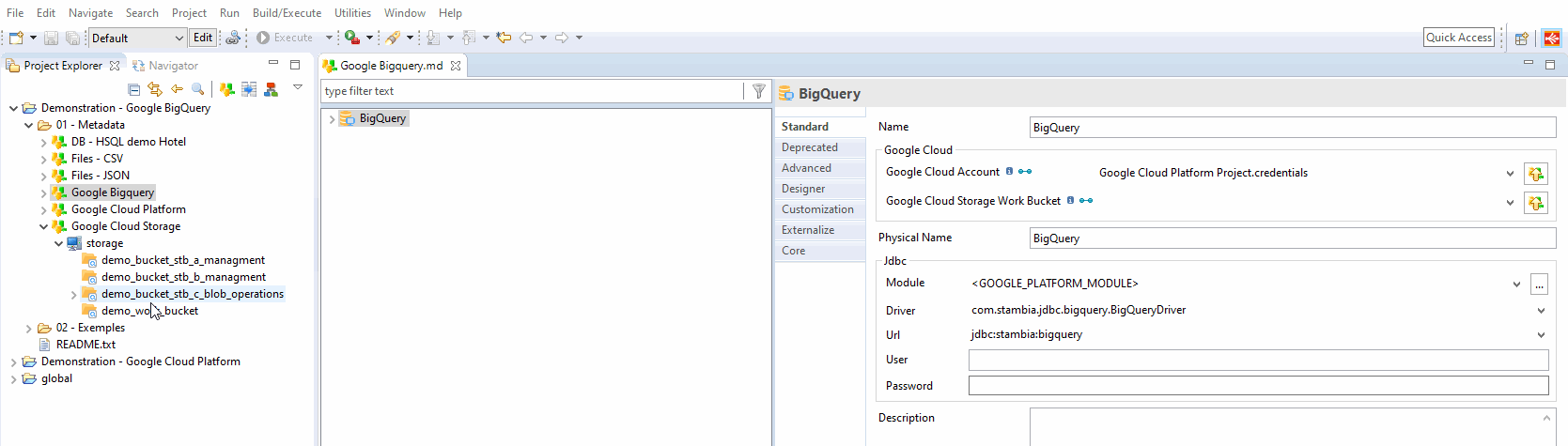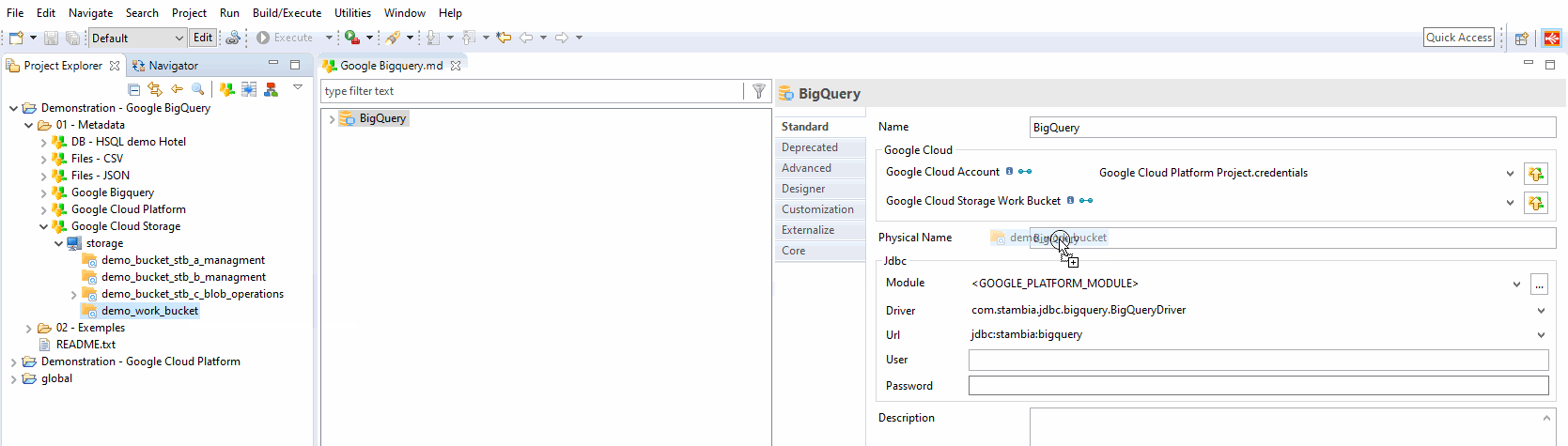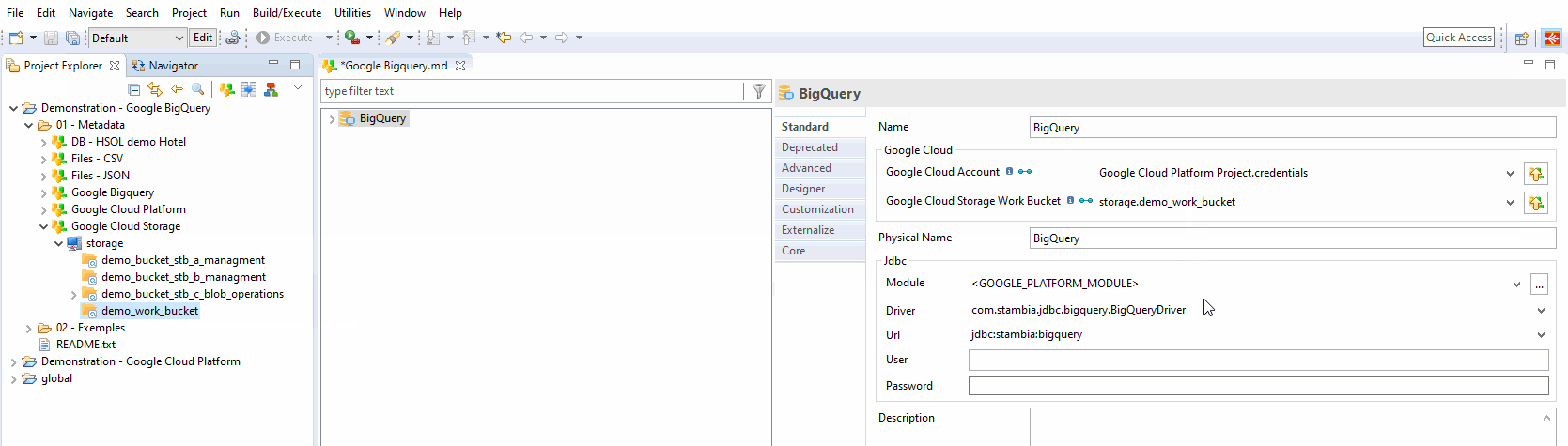
Define the Cloud Storage link
For performance purposes, Semarchy xDI is using Cloud Storage to optimize the data loading on Google BigQuery
Drag-and-drop or select your previously created Google Cloud Storage Metadata inside the related property.
Choose a bucket or a folder, depending on your preferred organization.
| This bucker/folder will be used as the temporary location when necessary, to optimize data loading into Google BigQuery. |
Create your first Mappings
Below are some examples of Google BigQuery usages in Mappings and Processes.
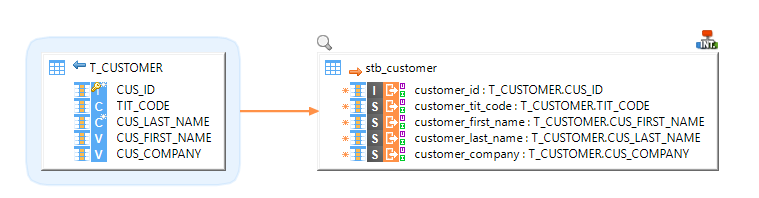
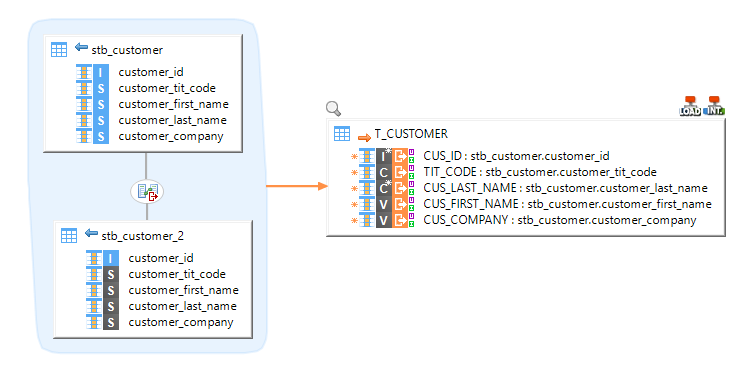
Example of Mapping loading data from an HSQL database to a Google BigQuery table
Example of Mapping loading data from multiple BigQuery tables with joins to an HSQL table
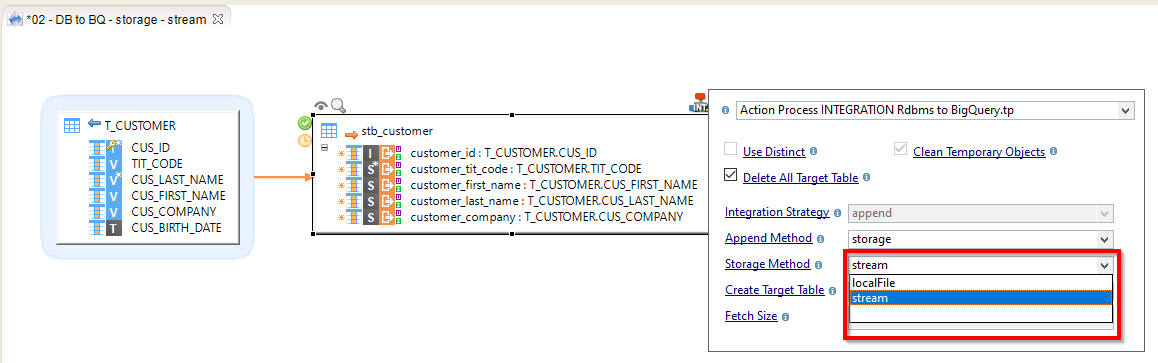
Cloud Storage Mode
When integrating data into Google BigQuery, data may be going through Google Cloud Storage for performance purposes.
Depending on the amount of data sent and network quality, for instance, different methods are available in Templates to have better performances.:
-
stream: Data is streamed directly in the Google Storage Bucket.
-
localfile: Data is first exported to a local temporary file, which is then sent to the defined Google Storage Bucket. This method should be preferred for large sets of data.
The storage method is defined on the Template:
Sample Project
The Google BigQuery Component ships sample project(s) that contain various examples and use cases.
You can have a look at these projects to find samples and examples describing how to use it.
Refer to Install Components to learn how to import sample projects.