| This is documentation for Semarchy xDI 2024.1, which is no longer actively maintained. For more information, see our Global Support and Maintenance Policy. |
Serialize source data
This document describes how to use the serializer in mappings.
The serializer reads textual, structured data such as a JSON file, and processes the data so it can be embedded in a field within a target datastore. It is useful in situations where you want to process your structured data from within a database to take advantage of RDBMS tools and workflows.
The serializer templates offered in mappings are based on the computed input format. For example, when the input is in JSON format, you will see options for a JSON serializer.
Refer to Templates for the current list of currently supported formats and templates.
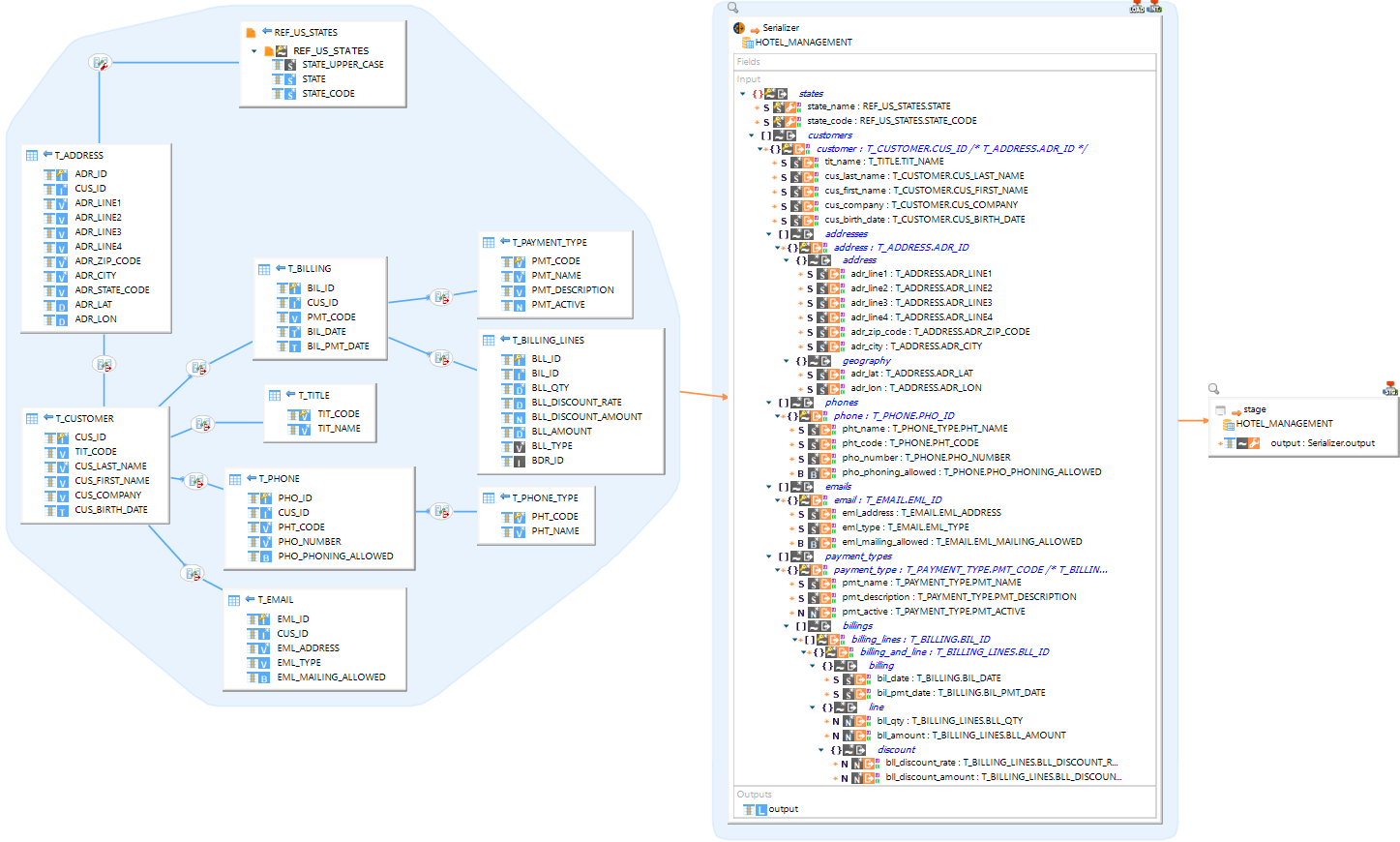
Create a serializer
To create and configure a serializer in a mapping:
-
Choose a database schema that will be used as a backend engine to process the data.
-
Drag and drop the database schema into a mapping.
-
From the menu that appears, select the Create Serializer option.
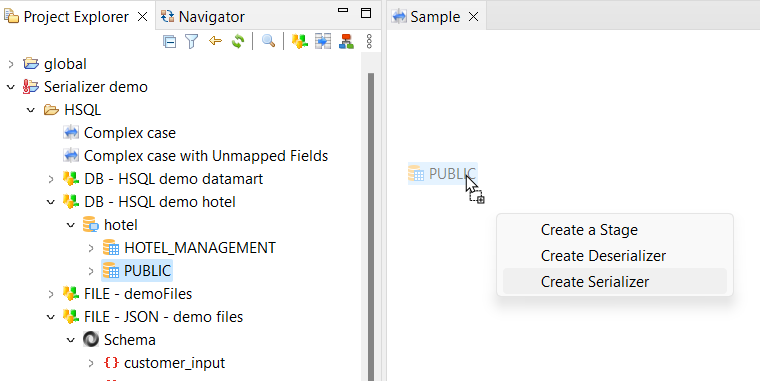
-
Add fields (Optional).
Configure a serializer
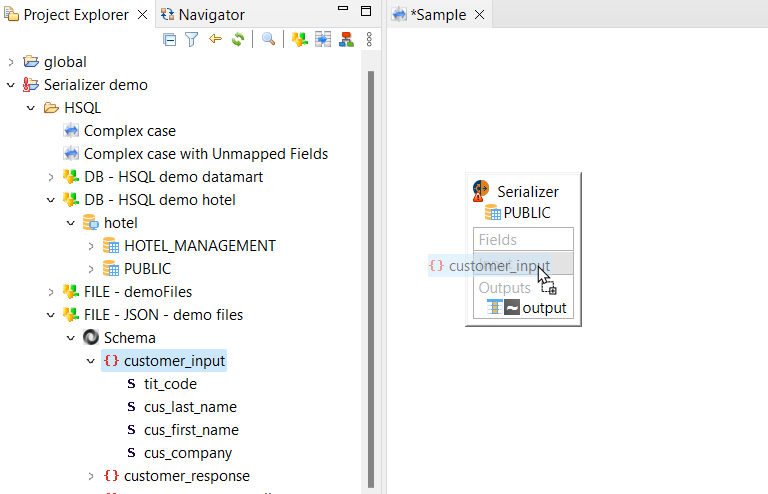
Add input
The input is a reverse-engineered metadata representing a data structure, such as a JSON metadata, that will be serialized.
To define the serializer input, find a previously reverse-engineered metadata representing structured data, and drag and drop it from the Project Explorer onto the input field.
Set output
The Output is a datastore field containing embedded semi-structured data.
When you execute the mapping, the structure in the input field is serialized into more simple string data, then loaded into the output structure. Finally, the data from the output is loaded into the mapped fields in the target datastore.
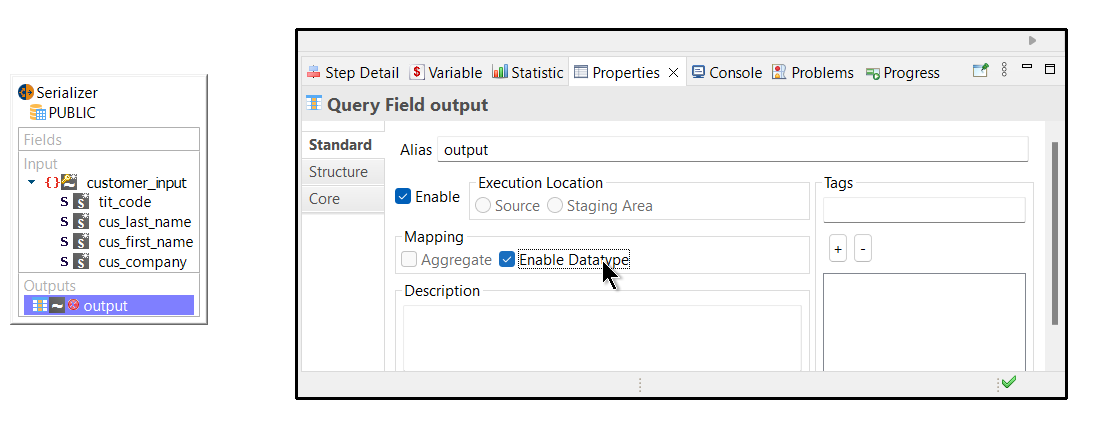
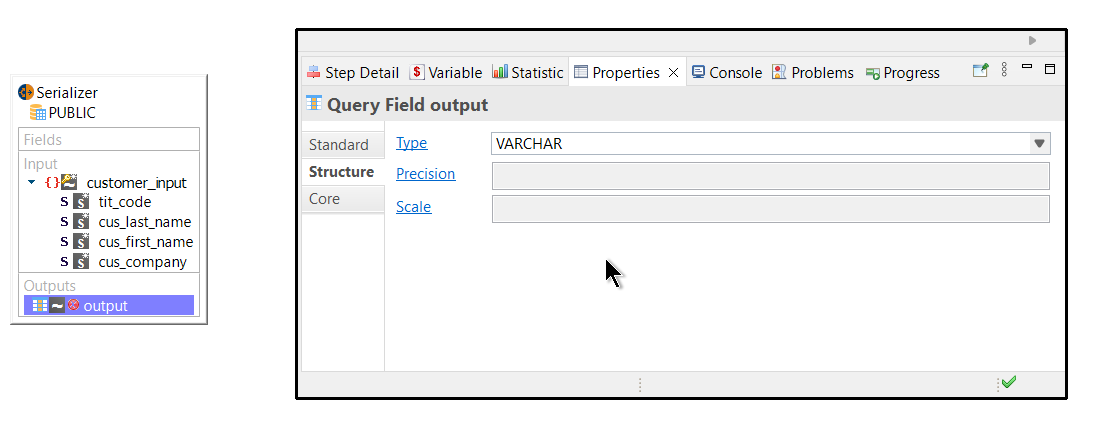
In order to work properly, the Output field must have its type correctly set by following these steps:
-
Click on the Output field.
-
In the Properties > Standard view, click Enable Datatype+
-
In the Properties > Structure view, activate the Type field and select the data type that corresponds to the mapped field in the target datastore.+
Add fields
Serializer fields are optional containers to store source column data alongside the output structure data. Create fields when you need to load and process data from other datastores, or when you need to join two serializers.
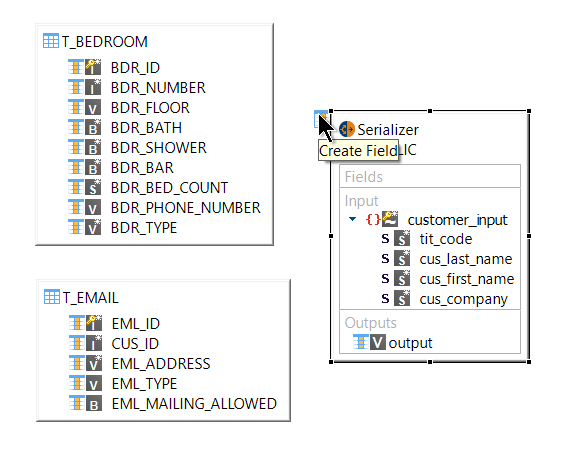
To add serializer fields:
-
In the top left corner of the serializer, click the create field icon.
-
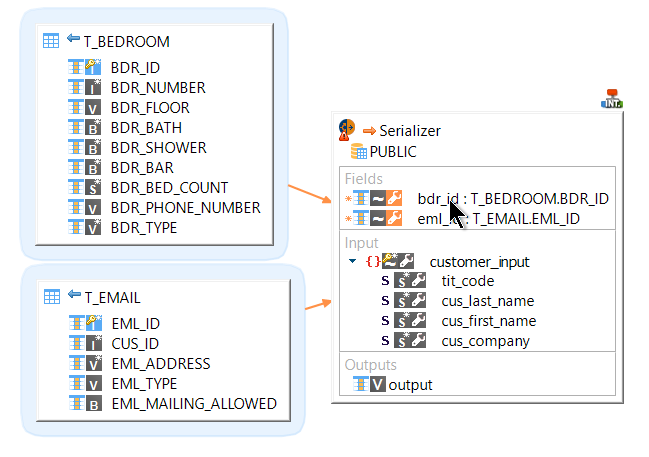
Drag and drop a field from the source datastore onto the one you just created.
-
Select one of the Map options.
-
Repeat the procedure for any other fields you need.
You can now use the fields the created as a source to map a target datastore, or use them to join the serializer with other datastores.
Join serializers
You may have more than one serializer in your mapping. In such a scenario, you can join them using fields.
To join two serializers:
-
Select a serializer and add the fields containing the data to be used for the join. See Add fields.
-
Repeat the procedure for the other serializer.
-
Drag and drop the field from one serializer on the field in the other serializer.
The two serializers are joined. Use them as a source to load target datastores.