| This is documentation for Semarchy xDI 2023.1, which is no longer supported. For more information, see our Global Support and Maintenance Policy. |
Getting Started with Avro
Overview
This getting started gives the basics to start working with Avro with Semarchy xDI.
Avro is a data serialization format formalized through a JSON-like structure and stored inside binary files.
The data structure is described within an Avro schema which is usually shipped within the binary file, alongside the data.
| Refer to Apache Avro Specification for further information. |
Metadata
Creation
To create an Avro metadata:
-
Start the metadata creation wizard.
-
Select Avro in the list.
-
Click Next, select a Module, then click Finish.
Reverse-engineering
The Avro data structure is defined in an Avro schema that is usually provided either:
-
Inside a separated Avro schema file formated as JSON.
-
It is usually identified with the .avsc file extension.
-
-
Inside the Avro binary data file.
-
It is usually identified with the .avro file extension.
-
| Avro component supports reverse-engineering schemas provided with these two methods. Use your preferred method for reverse-engineering depending on your situation and the resources you have at your disposal. |
| Avro data structure can also be designed manually in Metadata. Refer to the Definition section. |
Reverse-engineering operation
To reverse-engineer the Avro metadata:
-
Define the reverse URL.
-
AVSC Reverse URL to reverse from an Avro schema file.
-
AVRO Reverse URL to reverse from an Avro data file.
-
-
Right-click the root node, choose Actions, then select the corresponding operation.
-
Reverse From AVSC to reverse from the defined Avro schema file.
-
Reverse From AVRO to reverse from the defined Avro data file.
-
The URL can refer either to:
-
A local file path, using the following syntax: file:///<file-path>;
-
An URL, using the following syntax: http[s]://<url-path>
Below, is an example of reverse-engineered metadata:
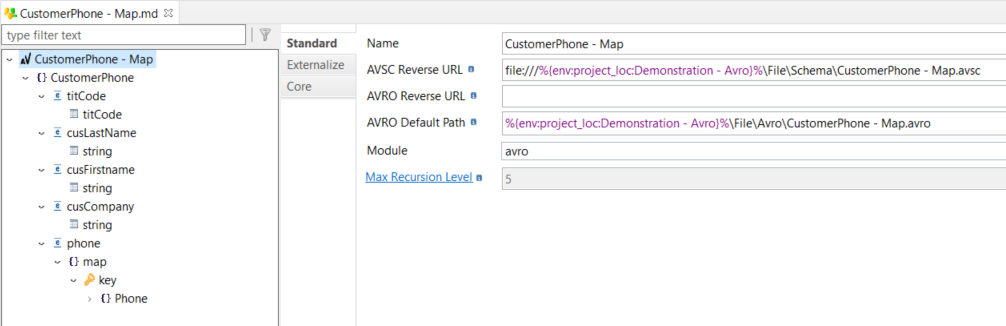
Definition
The Avro metadata can be edited and defined manually.
All the Avro types and references can be designed and configured in metadata through the related nodes.
This section describes the main metadata nodes that can be created and configured.
|
The content of the New context menu available on each node is adapted to the context. As an example, a field can only be added under a record, a map must have a key, which contains values, and more… |
|
The Avro schema corresponding to the designed metadata can be generated. To generate it, use the toAvsc XPath function that is available on every node (except the root node which is only a container). Use the result of the function accordingly to your requirement. For a quick check, you can display the result in the designer console. Right-click a node, select XPath, then toAvsc. |
Record, array, map
Avro records, arrays, and maps are containers that usually contain underlying structures.
They can be added, designed, and configured in the metadata.
To add a new record, array, or map:
-
Right-click an applicable node, select New, then record, array or map.
-
Edit the record’s properties accordingly to your requirements.
| The underlying structure of records, arrays, and maps must be designed. Refer to the sections related to the related underlying nodes. |
Example of a record, with its underlying structure:
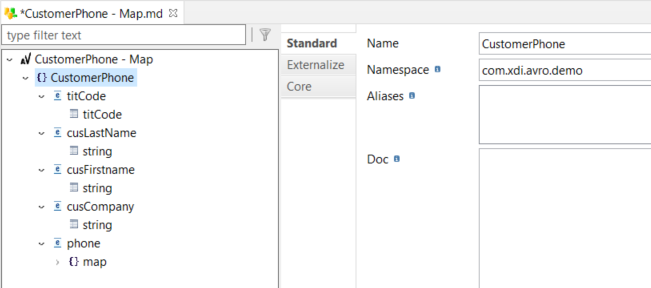
Example of an array, with its underlying structure:
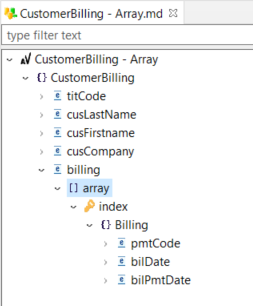
Example of a map, with its underlying structure:
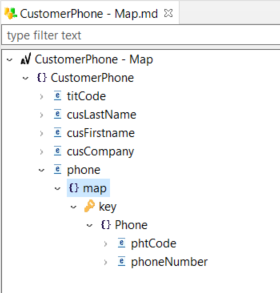
Field
Avro fields can be designed and configured.
Right-click an applicable node, select New, then field.
Finally, define or edit the field’s properties accordingly to your requirements.
| The underlying structure of a field must be designed. Refer to the sections related to the related underlying nodes. |
Example of a field, with its underlying structure:
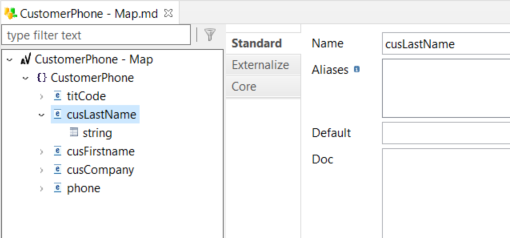
Primitive, fixed, enum
Primitive (value), fixed, or enumeration nodes can be designed and configured.
These Avro types represent the Avro data values. When reading or writing Avro files, data is stored inside these nodes.
To create one of these nodes:
-
Right-click an applicable node, select New, then value, fixed, or enum.
-
Finally, define or edit the node’s properties accordingly to your requirements.
Example of a primitive (value) node:
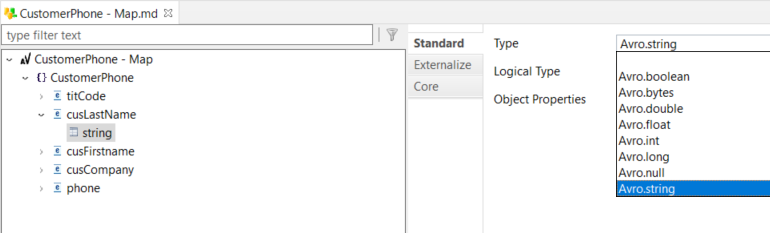
Example of a fixed node:
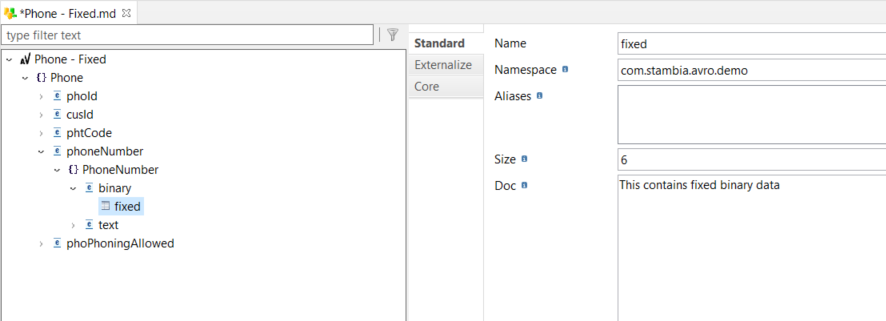
Example of an enum node:
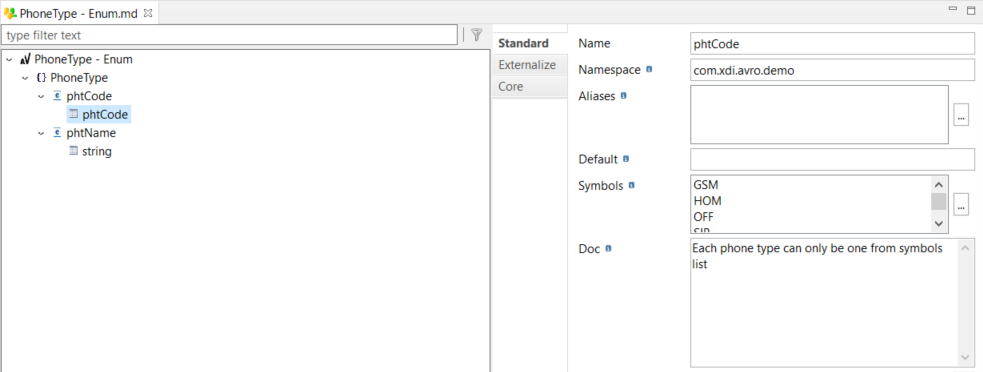
Key and index
The key and index nodes are related to map and array containers.
Every map container must have a key node, and every array container must have an index node.
They are used to identify the values contained in these containers.
To create a key or an index: Right-click an applicable node, select New, then key or index.
Example of a map container with its key and underlying structure:
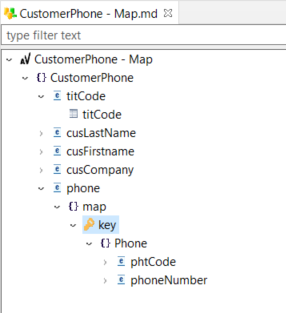
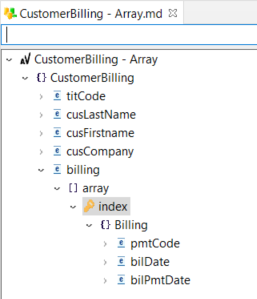
Example of an array container with its index and underlying structure:
Type Reference
The Avro schema supports having types defined through a reference to another type.
This allows reusing the definition of an already defined type.
The Avro component supports type references, that are represented in metadata as follow:
-
A Referencable Type node.
This node is a placeholder that represents a type that is referencable, which means a type that could be used as a reference.
It has a Name property that allows giving a logical name, and a Type attribute that allows selecting the type that is referencable.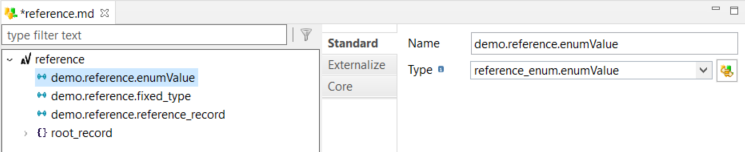
-
A Type Reference property on the applicable nodes.
This property allows selecting, on a type, a reference to another type. The list of possible references is populated from the previously defined referencable type nodes.
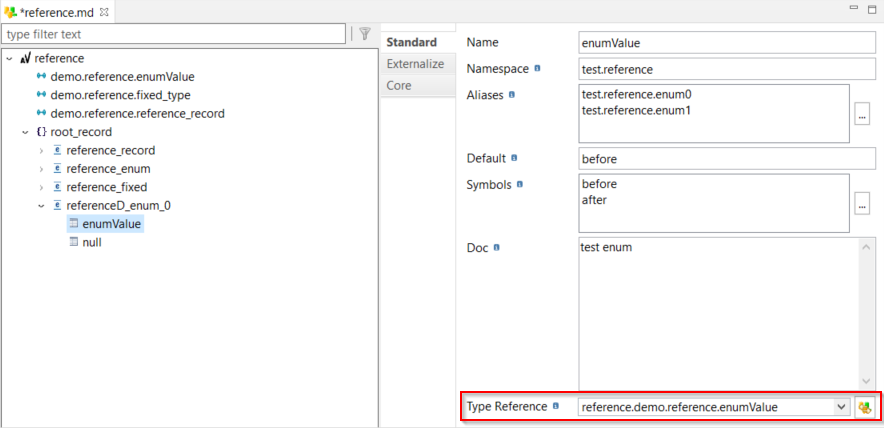
| When reverse-engineering an Avro schema, the Referencable Type nodes are automatically created and the Type Reference attributes automatically set when applicable. |
Create your first Mappings
The Avro metadata can be used in mapping to read or write Avro files.
This is similar to any common mapping writing files such as JSON files.
Read Avro files
Fully integrated data flows can be created to read Avro files.
Avro data can be retrieved and loaded in any other target datastore.
To read an Avro file:
-
Create a mapping.
-
Drag-and-drop the source Avro metadata.
-
Drag-and-drop the expected target metadata.
-
Map the fields accordingly to your requirements.
Make sure to map the nodes containing the real values, such as primitives (value), fixed, or enums.
Example of mapping loading Avro data into a target database:
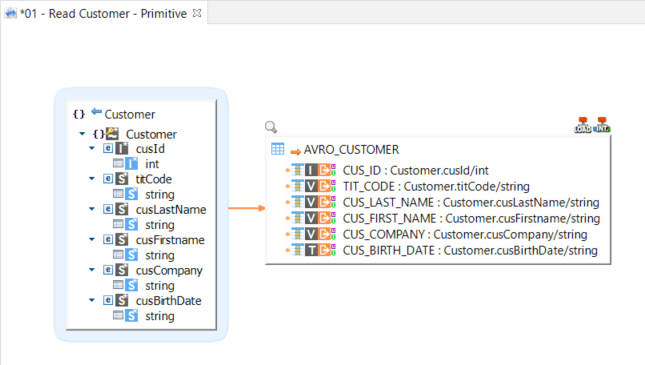
| The Avro file path is defined in the AVRO Default Path property in the metadata. You can overwrite it in the In File Name parameter of the load template. |
| Make sure to use the Load XML to RDBMS template. |
Write Avro files
Fully integrated data flows can be created to write Avro files.
Avro data can be written from any source datastore.
To write an Avro file:
-
Create a mapping.
-
Drag-and-drop the source metadata.
-
Drag-and-drop the target Avro metadata.
-
Map the fields accordingly to your requirements.
There are several specificities on the Avro mapping to consider:
-
The source values must be mapped on the target primitives (value), fixed or enums nodes.
-
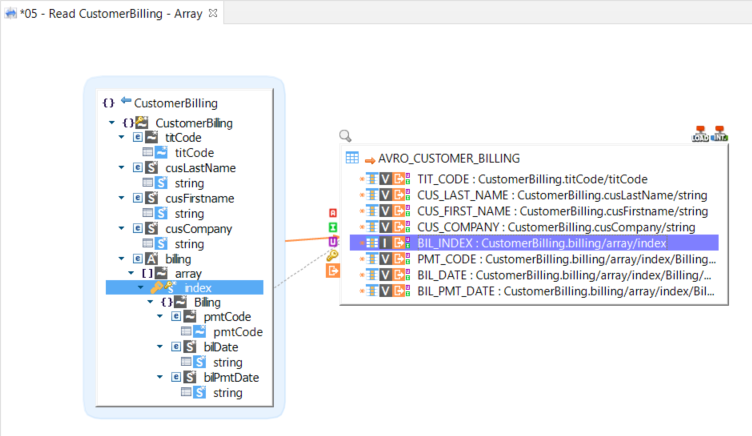
Repetition keys must be defined and mapped on the container nodes, if you want to iterate and create many iterations, such as on arrays.
Example of mapping writing data into an Avro file.
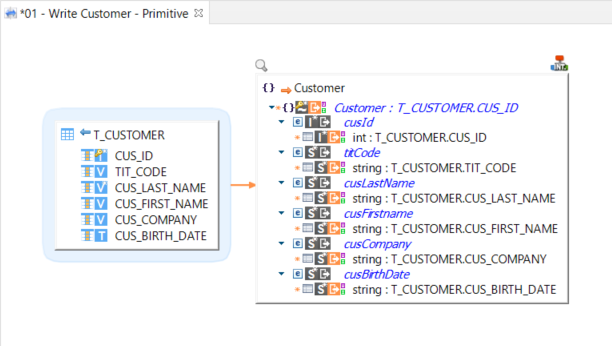
| The Avro file path is defined in the AVRO Default Path property in the metadata. You can overwrite it in the Out File Name parameter of the integration template. |
Write an array index (or a map key)
When writing an array, you have to use the index node as a repetition key, as shown in the below example.
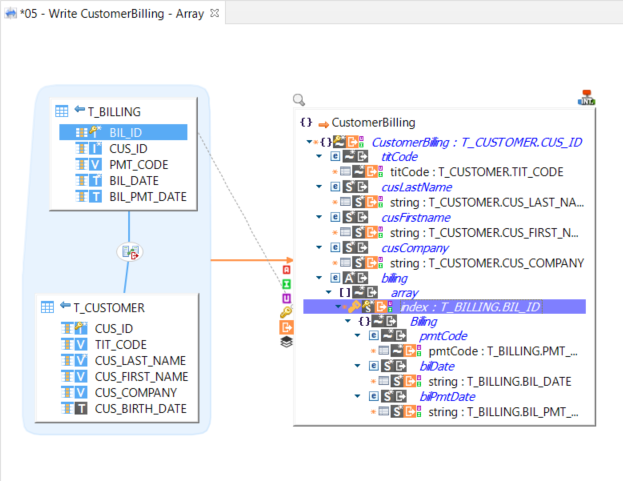
The same must be done for writing a map key.
Write unions
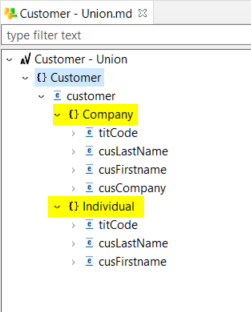
In Avro, the "union" notion allows a field to contain different underlying structures depending on the situation.
The Avro schema defines that a field can contain one record structure or another, and at write, we choose one depending on the requirements. Multiple structures are possible, however, only one is written in the target file.
In the metadata, unions are simply represented through fields having multiple underlying structures. This is up to the user to map the correct structure in the mapping, according to the situation.
Example of metadata:
Example of mapping:
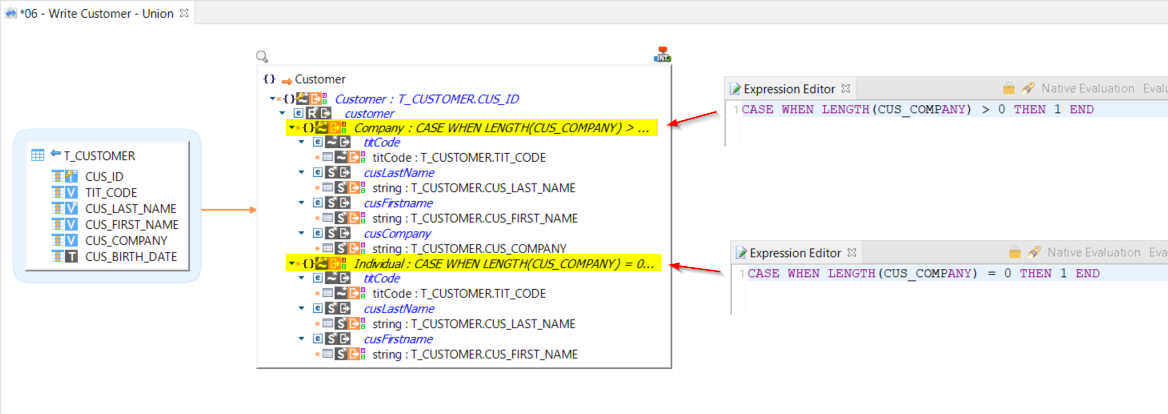
In this example, depending on the source data, the mapping will either map one or the other record.
To achieve this:
-
Repetition keys have been defined on the records.
-
A different condition has been added to each one.
-
The target primitive values have been mapped as usual.
Statistics
The Avro component produces standard statistics about reading and writing structured data.
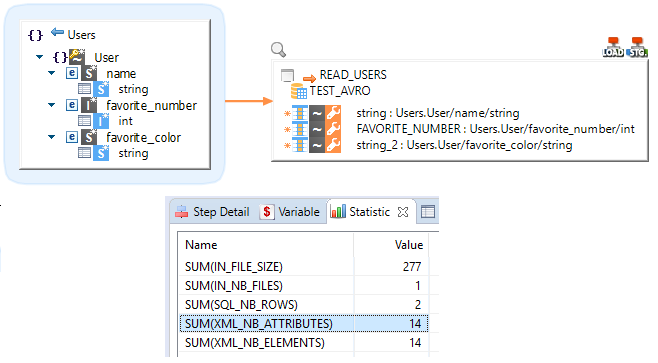
|
Each record, field, and value are counted has attributes and elements. In this example, the User node contains:
Therefore, there are 7 attributes/elements for 1 root record. Finally, as there are 2 root records in this file, we have a total of 14 attributes/elements. |
Miscellaneous
Consult Avro data
Avro files being binary files, they cannot be opened with standard text editors.
To consult Avro files' data, there are multiple methods.
We’ll describe two of them in this section:
-
Avro util command-line tool
-
Navigate the Avro Package available from Apache Download Mirrors.
-
Download the java/avro-tools-<VERSION>.jar file.
-
Run the tool in command-line with the corresponding options to read an Avro file’s data. There are many tutorials, documentation, and examples on the web, we recommend consulting them for further details.
Example of command:java -jar avro-tools-1.9.0.jar tojson --pretty /home/demo/avro/file.avro
-
-
Table load
-
Create a mapping in Semarchy xDI, with the Avro file as the source and a table as the target.
-
Run this mapping and, then run an SQL query to view the target table’s data.
-
Known Limitations
Below, is a list of the know limitations.
They may be unlocked in a future version.
-
Aliases can not be used in the mappings. They are reverse-engineered and editable in the metadata, but not yet supported in mapping.
-
Two records with, in the metadata, the same name but different namespaces, are not supported in mapping.
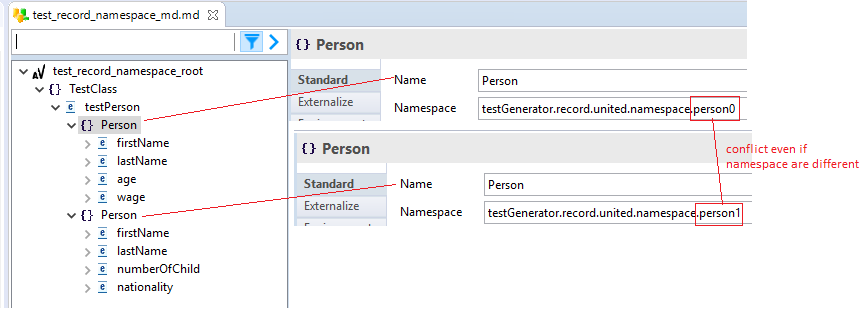
-
Union on primitives/fixed/enum types are supported when reading Avro files but are not supported yet when writing Avro files.
Sample Project
The Avro Component ships sample project(s) that contain various examples and use cases.
You can have a look at these projects to find samples and examples describing how to use it.
Refer to Install Components to learn how to import sample projects.