| This is documentation for Semarchy xDI 2023.1, which is no longer supported. For more information, see our Global Support and Maintenance Policy. |
Getting Started with Privacy Protect
Overview
This getting started gives some clues to start working with Privacy Protect Component.
Privacy Protect Component allows anonymizing, pseudonymizing and generating data in databases. It gives the capability to companies to comply with GDPR (General Data Protection Regulation).
| GDPR is a European directive to protect personal data. This new regulation replaces 1995 data protection laws and entered into force the 24 th May 2016 and is mandatory for all companies, administrations or European organisms, from the 25th May 2018. |
Prerequisites
Import the Reference Project
Privacy Protect Component requires a reference project to load the standard dictionaries that are shipped within.
To import Privacy Protect reference project:
-
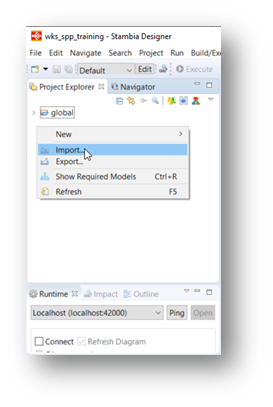
Right click in the Project Explorer View.
-
Choose "Import".
-
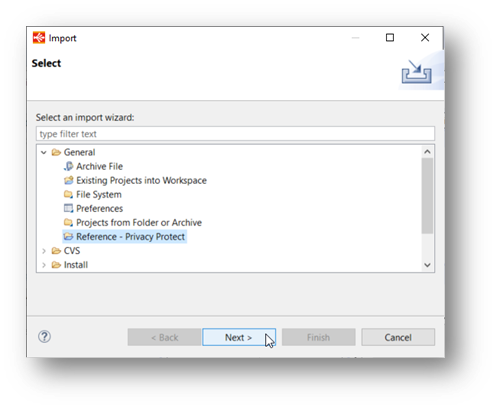
Then select "Reference - Privacy Protect" in the "General" folder.
-
Confirm the name of the reference project after pushing the next button.
Click on import:
Choose the reference project:
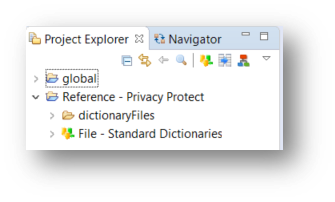
Privacy Protect reference project is created:
Configure the Metadata
Overview
To drive Personal Data protection in Privacy Protect, you must parametrize the tool at 3 levels in Metadata properties of a database, using the "Privacy Protect" view.
Schema level
It’s required to complete some of the following fields to configure the usage of privacy protect on the source schema:
-
Masks and database schemas to use
-
Default geographic coverage for the database schema to configure
Example:
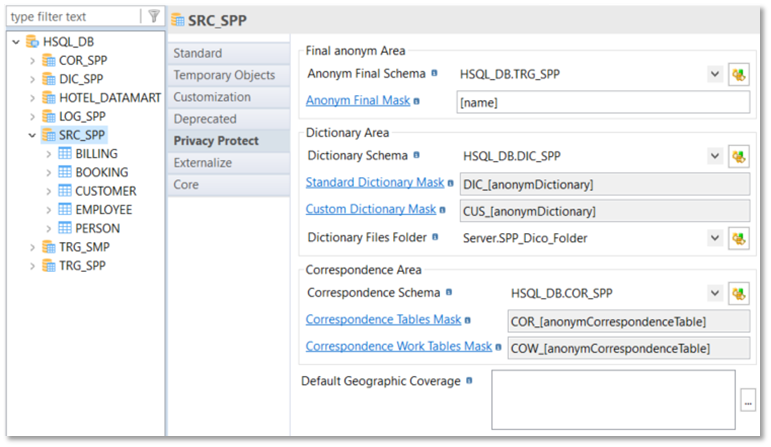
Table / Datastore level
It’s required to complete some of the following fields to configurate the usage of privacy protect on the required source datastores (to complete for each table involved in Privacy Protect usage):
-
Dependency with other tables
-
Table default geographic coverage
-
Row generation (to generate rows in empty tables)
-
Source data selection (filters and order by clause)
Example:
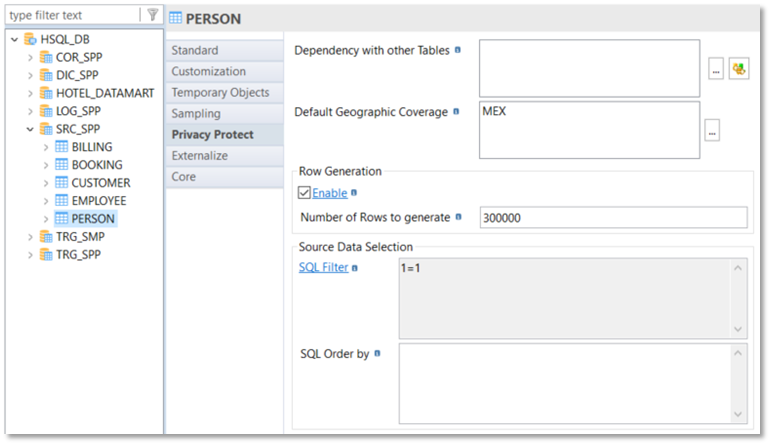
|
This is an example of an empty table needing 300000 rows to be generated for a Mexican (MEX) table default Geographic coverage. In this case, you will have to define methods on each column of each table, as described in the next chapter. |
Column level
It’s required to complete some of the following fields to configure the usage of privacy protect on the required source fields:
-
Dependency with other tables
-
Table default geographic coverage
-
Row generation (to generate rows in empty tables)
-
Source data selection (filters and order by clause)
Example:
| This is an example of a lastname column substituted using a "lastname" standard dictionary, with no NULL value generated, an init cap transformation applied on substituted lastname, a geographic coverage on several countries (FRA, DEU, ESP, GBR, MEX, and more…) and a generation not uniformly distributed. |
Privacy Protect methods
Overview
Different methods are available in Privacy Protect.
To apply the best protection on your data, you must choose the better method for each of your columns, depending on each data itself and on your business and technical context.
Substitution from dictionaries
Substitution from a standard dictionary
It is possible to substitute your personal values to protect by values contained in dictionary tables.
Indeed, Privacy Protect Component is shipped with some standard dictionaries. Those dictionaries can have several properties/columns.
Those dictionaries must be integrated in your database with "Load Standard dictionaries" tool in advance.
The standard dictionaries available are:
-
Address supplement
-
City
-
Company
-
Country
-
Email
-
Email provider
-
Family situation
-
Firstname
-
Lastname
-
Phone
-
Street
-
Zone1_iso
Example:
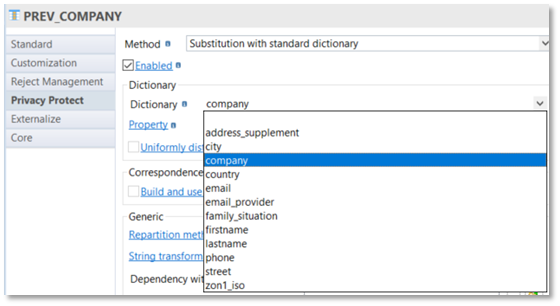
Once the dictionary is chosen, select the property of the dictionary to substitute:
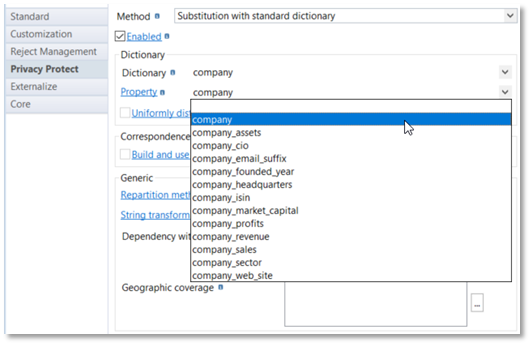
It is possible to drive the way to generate substitution values with the "Uniformly distributed" field. Choose if the random choice must be "Uniformly distributed" (depending on "population" [pop] column in the dictionary table) or not (each row has the same chance to be chosen).
Some "Standard dictionaries" (Email, Phone, Street) will require additional properties to work.
Substitution from a custom dictionary
With "Substitution with custom dictionary", Privacy Protect allows you to build and use your own dictionary and compute the population with each term retrieved.
You must give a name to each custom dictionary and use it directly on the same field or after in another field.
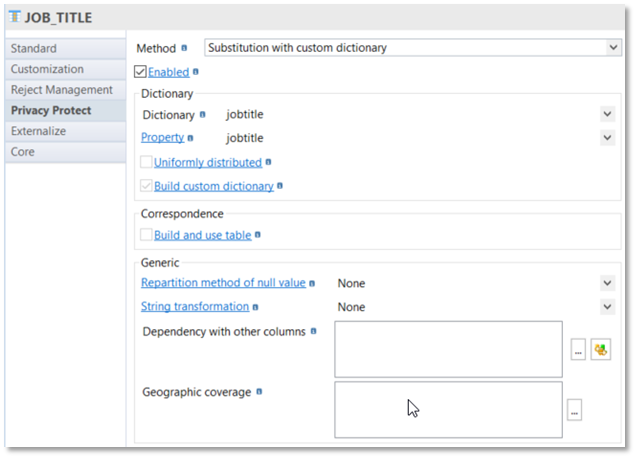
Deduction from dictionaries
Deduction from a standard dictionary
It is also possible to deduct some properties from "Standard dictionaries" when they are built with additional properties, like gender for the firstname or sector and email_suffix for company dictionaries.
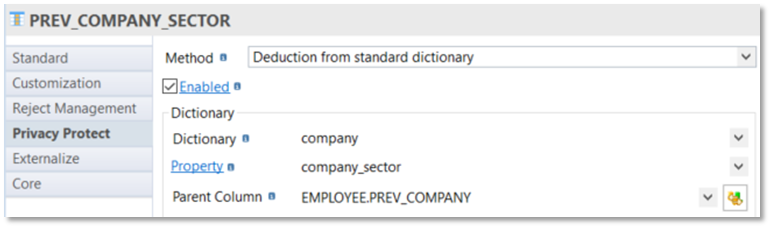
In this case, you need to specify the dictionary, the deducted property and the parent column allowing the deduction.
No need here to add a dependency with this other column: it will be done automatically in the tool.
Random generation
Another way to modify/generate values is to choose the random generation method.
It must be required to drive the way to generate random data through the Random generation type.
To specify it, you must answer two questions: . How to define the repartition characteristics? .. Preserved: The Component computes the repartition characteristics of the values for the source column .. Defined: You must specify the repartition characteristics for the values to substitute on target column . How to distribute random values? .. Uniformly: The Component will generate random values with the same chance for each value to be generated .. Not uniformly: The Component will generate random values following a binomial distribution
Depending on the data type (string, number, date/timestamp) of the column and the distribution method chosen, the component will require different properties, like minimum value, maximum value, mean value, standard derivation.
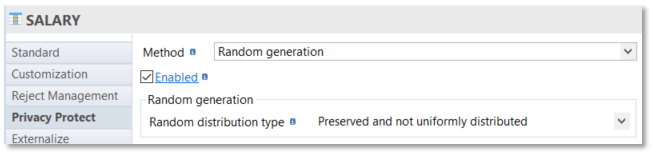
Example of random generation with preserved and uniform distribution:
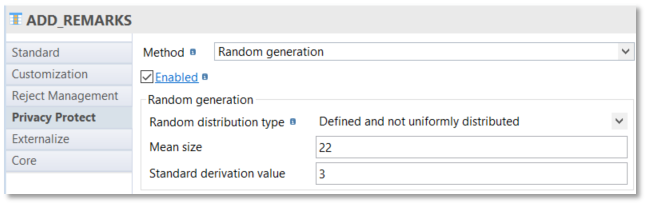
Example of random generation with defined and not uniform distribution:
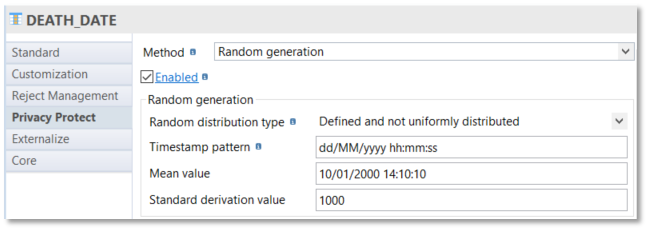
Another example of random generation with defined and not uniform distribution:
Text generation
Instead of random characters generation, it’s possible to generate one or several sentences, when columns need to be substituted or completed (row generation) with sentences.
Text generation build random sentences in the language corresponding to the chosen geographic coverage (if any) or in the following languages: French, Spanish, Italian, German, English.
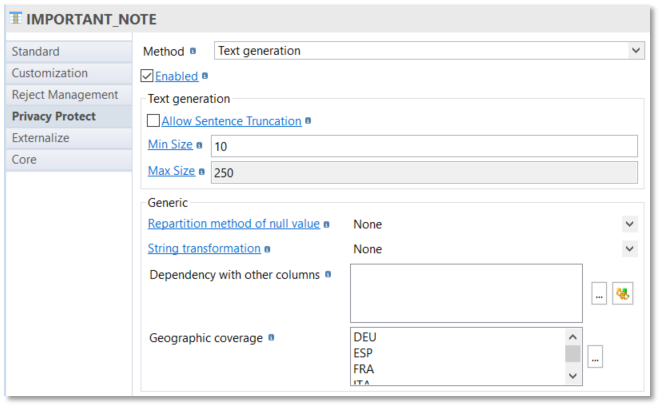
Check "Allow Sentence Truncation" box if you want to truncate sentences when max size is reached and choose the "Min Size" and the "Max size" of the text to generate.
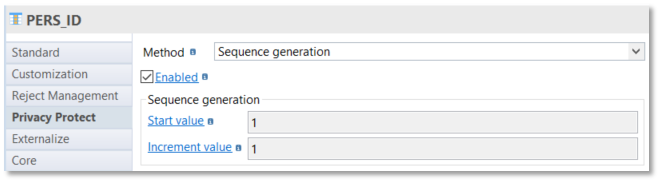
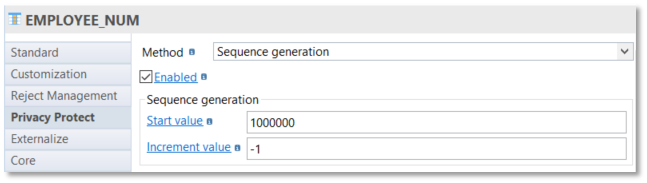
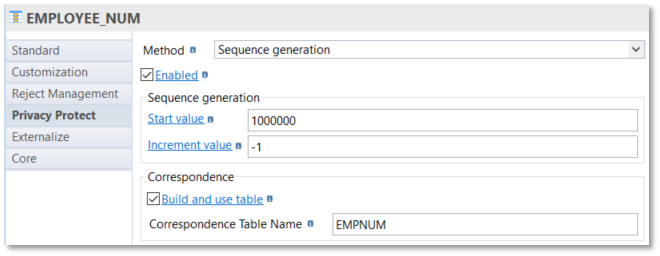
Sequence generation
Sequence generation allows to generate a sequence of number.
This functionality could be useful to complete technical internal identifier.
You must specify the Start value and the Increment value: Start value and Increment value can be decimal values and Increment value can be a negative value.
Obfuscation
Obfuscation allows to hide/transform a part of a column value: it’s often used to display partially a credit card number for example!
To specify obfuscation, you will have to use "Regular expression".
You must specify two fields:
-
Regular expression pattern to characterize the source field.
-
Replacement regular expression to explain how to realize the obfuscation.
Example:
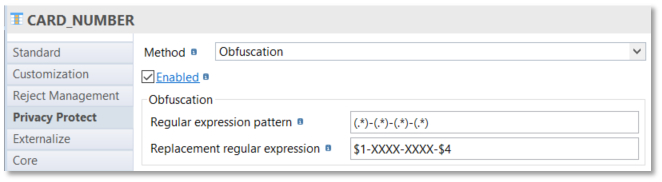
In this sample, a source credit card number is defined as several characters concatenated with " - " concatenated with several characters concatenated with " - " concatenated with several characters concatenated with " - " concatenated with several characters.
For example, 1234-4567-8794-8512.
The replacement will keep the first part ($1) and the fourth part ($4) and generate 1234-XXXX-XXXX-8512
A second example realize an obfuscation of the national insurance number:
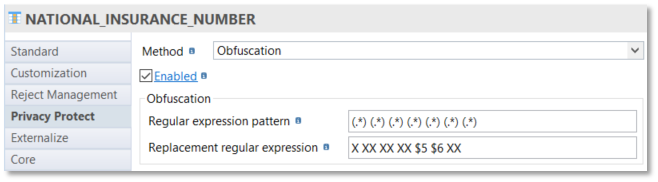
In this sample, a source national insurance number is defined as several characters concatenated with a space concatenated with several characters concatenated with a space concatenated with several characters concatenated with a space…
For example, 1 82 04 75 452 147 27.
The replacement will keep the 5th part ($5) and the 6th part ($6) and generate X XX XX XX 452 147 XX
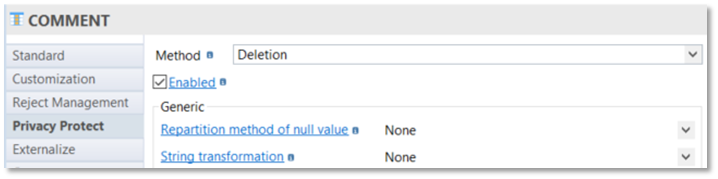
Deletion
Deletion allows simply to delete the column value: it’s a method to use when a field is not required to be kept.
Java transformation
Java transformation method allows to implement more complex transformation rules adding Java programming capabilities.
Other columns of the same table are available in the Java program, simply using their column names.
To set a value of the current column, just use the name of the column in an expression of variable assignment:
<COLUMN_NAME>=<VALUE>;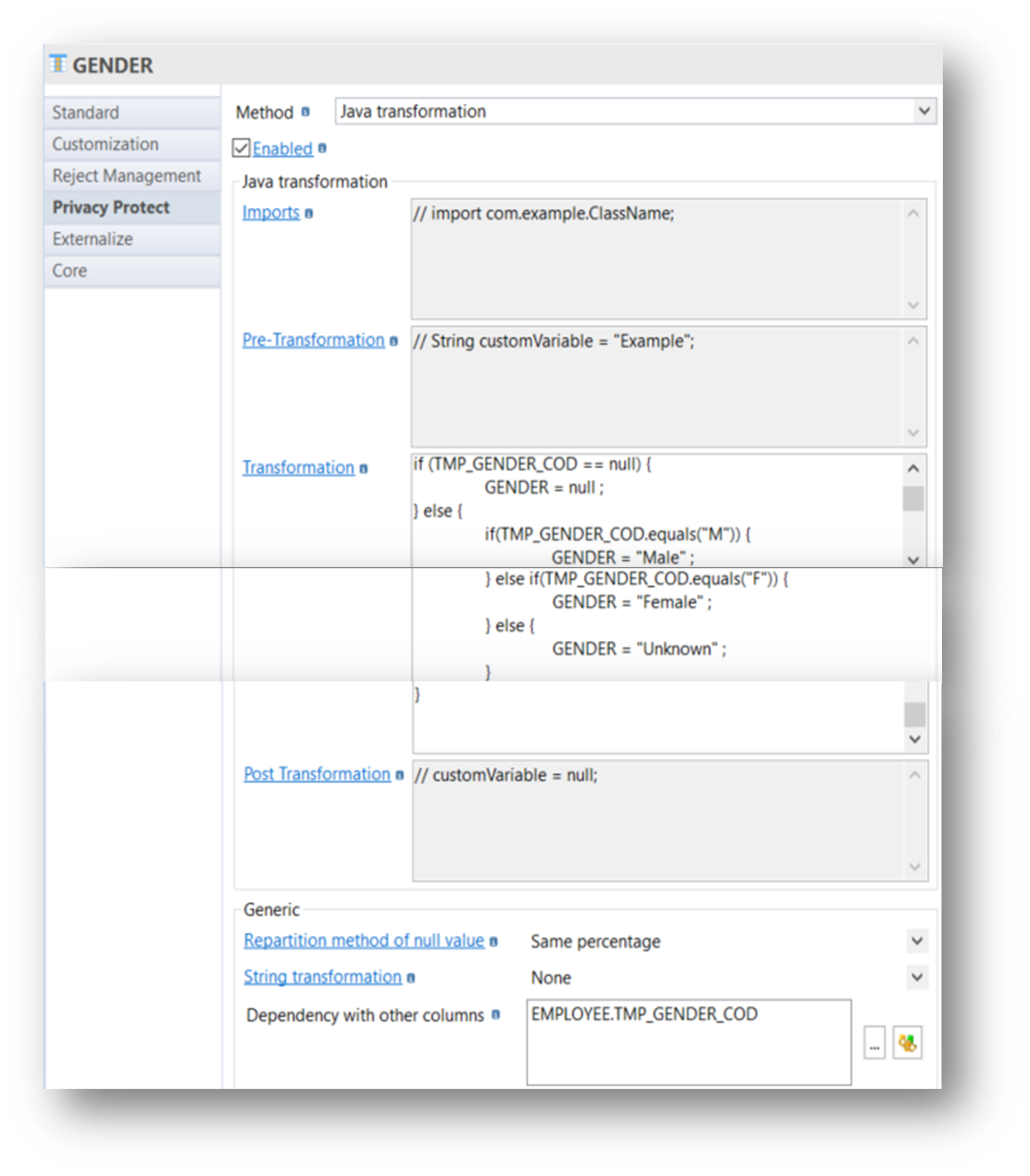
It is possible, if required, to add extra classes to import in the Java class that will be built in "Imports" field.
You can add in Pre-Transformation field the Java code that must be executed prior to the iteration on each record (typically variables declaration and initialization)
You can add in Transformation field the Java code that will be executed on each record.
You can add in Post Transformation field the Java code that must be executed after the iteration on each record (typically closing of flushing objects).
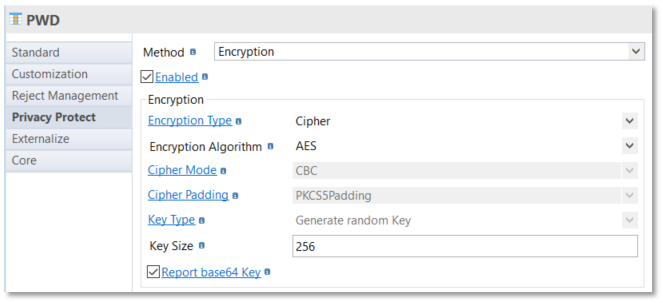
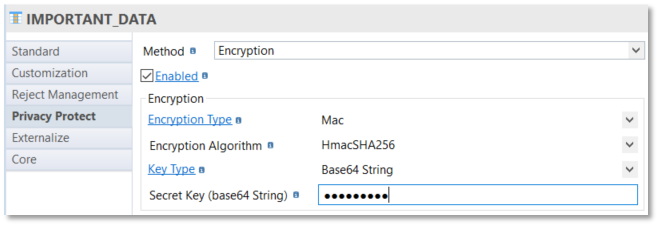
Encryption
Encryption can be used to protect data: It implements "Java encryption" capabilities, with two encryption types and different encryption algorithms, mode and padding and with a key type to define:
-
Encryption type: Cypher (default mode)
-
Algorithms: AES, ARCFOUR, Blowfish, DESede, RC2
-
Cypher mode: CBC (Default), CFB, CTR, CTS, ECB, NONE, OFB, PCBC
-
Cypher padding: PKCS5Padding (Default), ISO10126Padding, NoPadding, OAEPPaning, PKCS1Padding, SSL3Padding
-
-
Encryption type: Mac
-
Algorithms: HmacMD5, HmacSHA1, HmacSha256, HmacSHA384, HmacSHA512
-
-
With a key type to define
-
Generate random Key : create a random key for each execution (need to specify the key size)
-
Base64 String : Allows to manually specify the key to use for encryption (in Secret Key field)
-
Example with Cypher:
Example with Mac:
Correspondence table
A correspondence table must be used to replace each original value into the same target value. It can be used in several locations/columns.
Each correspondence table has two columns :
-
orig_key: original value
-
anon_val: target transformed value
A correspondence table can be used/enriched (not recommended from a protection point of view) or not on different runs of Privacy Protect.
From a legal point of view, a correspondence table must be secured or deleted after a run as you are able to retrieve the original value with it.
The build of a correspondence table must be done using another method (sequence generation in the bellow sample):
There is a dedicated method to use a correspondence method:
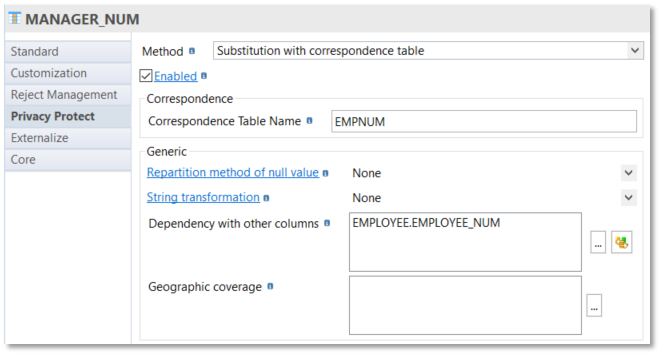
| if you have at least a correspondence table built in one column to protect, you need to use Privacy Protect tool twice. The 1st occurs of privacy protect tool must be in "initialization" Execution Mode (to integrate all the values in the correspondence table) and the 2nd in "anonymization" (default) Execution mode (to use the correspondence table). |
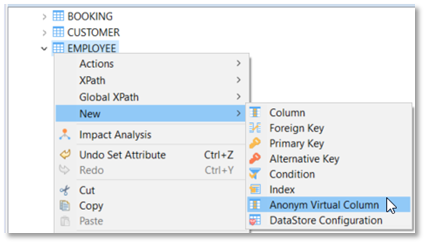
Anonym virtual column
Anonym virtual columns allow to produce intermediate transformation before using those virtual columns in the specification of a "real" column to protect.
Those virtual columns do not need to be added as a dependency with other columns for the real column and are not generated on target tables.
To add an "Anonym virtual column" to a table, it must be done on the required table in a Metadata:
Then, you can specify a transformation method on that column:
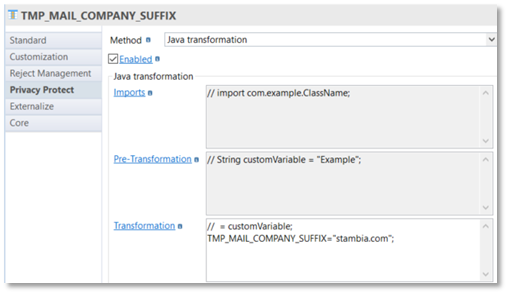
And finally use this virtual column to complete a "real" column:
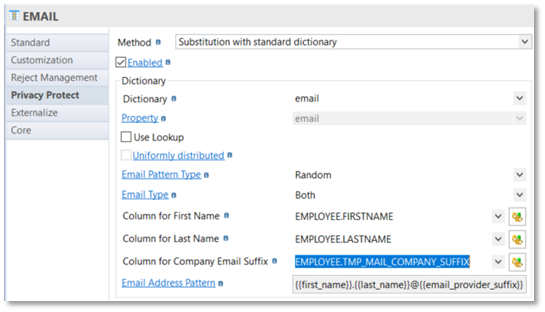
Run Privacy Protect
Overview
Privacy Protect Component provides several Process Tools.
These Process Tools are used to load the dictionaries, produce reports, run and apply all the rules defined in the Metadata.
Data catalog tool
Data catalog tool allows to share the list of protected data with all the actors involved before applying the protection and giving availability to authorized users.
This tool is available in the process palette, in Privacy Protect category, producing an HTML list.
You must use "Data Catalog" tool in a Process.
You have to Drag & drop the source schema on which applying the Data protection and a folder where the logs will be generated:
An HTML report file is generated in the defined log folder and must be shared with the dedicated actors to validate the data protection to apply.
Example of generated file:
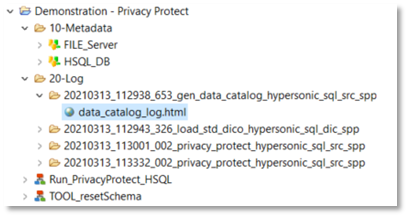
Example of file:

Load Standard Dictionary tool
Standard dictionaries need to be initialized (loaded) if you use them.
"Load Standard dictionaries" tool is available on process Palette in the Privacy Protect category.
You must use it in a Process and drag & drop :
-
The source schema with the dictionary schema defined at schema level
-
A folder where the logs will be generated

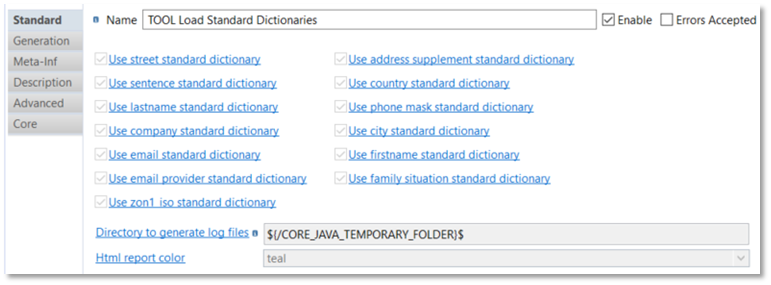
Then define the properties accordingly to your needs:
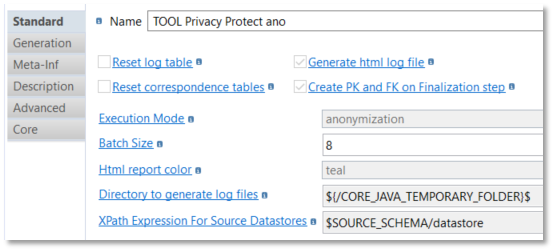
Privacy Protect tool
Privacy Protect tool applies all the protection methods defined in the metadata of the source schema and integrate them in the target schema.
Two "Execution mode"(s) are available :
-
Initialization to integrate data in correspondence tables (only required if correspondence tables are used)
-
Anonymization (default value) to apply all the protection methods in the target schema
"Privacy Protect" tool is available in the process Palette under Privacy Protect category.
You must use Privacy Protect tool in a Process and drag & drop:
-
The source schema on which the Data protection will be applied
-
A folder where the logs will be generated

Then define the properties accordingly to your needs:
Sample Project
The Privacy Protect Component ships sample project(s) that contain various examples and use cases.
You can have a look at these projects to find samples and examples describing how to use it.
Refer to Install Components to learn how to import sample projects.